超低标注需求,实现医学图像分割,UCSD提出三阶段框架GenSeg
GenSeg用AI生成高质量医学图像及对应分割标注,在仅有几十张样本时也能训练出媲美传统深度模型的分割系统,显著降低医生手工标注负担。
医学图像语义分割是现代医疗中的关键环节,广泛应用于疾病诊断、治疗规划、手术辅助等任务中。从皮肤病变到眼底病灶、从肿瘤边界到器官结构,精准的像素级分割结果对于临床医生具有极高价值。
随着深度学习的发展,医学图像语义分割的准确性显著提升,但一个普遍的核心难题依然存在——对大量高质量标注数据的依赖。
在医疗领域中,标注一个分割样本意味着:专业人员需逐像素勾画病灶区域;每张图像的标注常耗时数十分钟甚至更久;而且数据受限于隐私保护等合规限制。
这使得我们在许多真实临床场景中,面临超低数据的困境:数据少,难以训练出性能可靠的模型;而没有数据,则深度学习寸步难行。
尽管已有一些尝试(如数据增强、半监督学习),但它们仍存在关键局限:数据增强和分割模型训练分离,生成的样本无法很好的提升分割模型的性能;半监督方法依赖海量未标注图像,而这些在医疗领域仍存难以获得。
针对上述问题,加州大学圣地亚哥分校的研究团队提出了GenSeg,一种用于训练语义分割模型的三阶段框架,该框架中数据增强模型的优化和语义分割模型的训练紧密耦合,确保了数据增强模型生成的样本可以有效的提升分割模型的性能。
论文地址:https://www.nature.com/articles/s41467-025-61754-6,代码地址:https://github.com/importZL/GenSeg
GenSeg可以被应用到不同的分割模型,比如UNet和DeepLab来提升他们在in-domain(测试数据和训练数据来自于同一数据集)和out-of-domain(测试数据和训练数据来自于不同数据集)场景下的性能。
通过采用对应的数据生成模型和语义分割模型,GenSeg可以被应用到3D数据分割任务。
GenSeg三层优化训练框架
该论文近日被国际著名期刊NatureCommunications正式接收。
第一作者为博士生LiZhang,通讯作者为该校副教授PengtaoXie,团队其他成员还包括BasuJindal,AhmedAlaa,RobertWeinreb,DavidWilson,EranSegal,JamesZou。
技术核心
GenSeg包含两个主要组件:
1.语义分割模型,负责预测输入图像的语义分割掩膜;
2.掩膜到图像的生成模型,用于预测输入掩膜对应的图像。
其中GenSeg对普通的生成模型进行了修改,使其的模型结构可以在训练过程中进行优化。
整个GenSeg框架由三个阶段构成,采用端到端的训练方式:
首先,我们使用真实的图像-掩膜来训练生成模型的参数,其模型结构在该阶段是固定的;
接下来,对真实分割掩膜进行增强,生成新的掩膜,再通过使用上一阶段训练好的生成模型生成对应的医学图像,构成合成图像-掩膜对,将其与真实样本共同用于训练分割模型;
最后,将训练好的分割模型在真实验证集上评估,并根据验证损失反向更新生成模型的结构。
之后再次进入阶段1,开启新一轮的训练-生成-优化循环,直至收敛,可以将上述过程整合成一个多层优化框架:
其中,G表示数据生成模型中的生成器,H表示数据生成模型中的判别器,A表示生成器的模型结构参数,S表示语义分割模型,
表示用于训练生成器的数据,
表示用于训练分割模型的数据,
表示用于更新生成器结构的验证数据。
GenSeg通过一个以分割性能为直接优化目标的多层级优化过程,生成高保真度的图像-掩膜对,确保合成数据不仅质量优异,同时能有效提升下游模型的训练效果。
不同于传统的数据增强方法,GenSeg实现了与分割任务深度耦合的端到端数据生成;也区别于半监督方法,GenSeg无需依赖任何额外未标注图像。
作为一个通用、与模型无关的框架,GenSeg可以无缝集成到现有的医学图像分割模型中,助力构建更高效、更低成本的训练体系。
实验结果
相比传统方法,GenSeg在显著减少训练样本的同时,仍可达到相当甚至更优的分割性能。
不同方法在训练样本数量(x轴)与分割性能(y轴)之间的关系。
越接近图中左上角的方法,表示越具样本效率(即用更少数据达成更高性能)。
在所有实验中,GenSeg的表现始终接近左上角,远优于主流基线方法。子图a和b分别表示在in-domain和out-of-domain场景下的实验结果。
在in-domain实验中,GenSeg显示出显著的样本节省效果,比如在足部溃疡分割实验中,要达到Dice分数约0.6,UNet需600张图像,GenSeg-UNet仅需50张,减少12倍的数据量;
在out-of-domain实验中,在皮肤病变分割任务中,GenSeg-DeepLab仅使用40张ISIC图像即可在DermIS测试集上达到Jaccard指数0.67,而标准DeepLab在使用200张图像时仍未达到这一水平。
通过和分离式策略对比,GenSeg的端到端数据生成机制的合理性得以验证。
在分离式策略中,图像生成模型与分割模型是分开训练的:首先训练好生成器后固定,然后再用其生成的数据去训练分割模型。
实验结果表明,GenSeg的端到端联合优化机制显著优于分离式策略。
比如,在胎盘血管分割任务中,GenSeg-DeepLab实现了0.52的Dice分数,相比之下Separate-DeepLab仅为0.42
研究人员进一步探究了GenSeg的优势是否依赖于某一类特定的生成模型。
默认情况下,GenSeg使用的是基于GAN的Pix2Pix模型。
为此,实验中额外测试了两种替代生成模型:基于扩散模型的BBDM和基于变分自编码器的Soft-introVAE。对于每种生成模型,都分别测试了分离式训练与端到端训练两种策略。
上图中的实验结果清晰地表明两点:
1.无论使用哪种生成模型,端到端训练策略几乎总是优于分离式训练策略;
2.在所有组合中,端到端的扩散模型(BBDM)通常带来最优的分割性能,但通过实验发现它也带来了显著更高的计算成本。
这说明端到端优化机制是GenSeg成功的通用核心原则,不依赖特定模型;更强大的生成模型(如扩散模型)在性能上确有进一步提升空间,但需权衡计算效率与成本。
总结
GenSeg通过创新的端到端生成式框架,成功突破了医学图像分割中极少标注数据难以支持模型训练的关键瓶颈。
不同于传统生成模型将数据生成与图像分割训练分开来的做法,该方法通过多层级优化策略实现端到端的数据生成流程,将模型结构可优化的条件式生成模型与图像语义分割模型深度耦合,使分割性能直接反向指导数据生成过程,从而生成更有助于提升分割效果的样本。
GenSeg在涵盖多种疾病、器官与成像模态的11个医学图像分割任务和19个数据集上展现出强泛化能力。
在同域与跨域设定下均可带来10–20%的绝对性能提升,且所需的训练数据量仅为现有方法的1/8到1/20,大大提高了深度学习在数据匮乏医学图像场景下的可行性与成本效率。
-
超低标注需求,实现医学图像分割,UCSD提出三阶段框架GenSeg
GenSeg三阶段框架端到端生成医学图像及标注,数据需求减至120,性能提升10-20%。
2025-08-17 07:05:47 -
奥特曼曝惊世预言:2035年GPT-8治愈癌症,人类将为算力爆发三战
GPT-5上线引争议,奥特曼预言AI治癌与算力战,OpenAI重奖团队。
2025-08-17 07:05:39 -
物理AI如何变革机器人产业?英伟达与宇树、银河通用创始人闭门会全实录
AI与机器人协同进化,迈向下一个科技时代
2025-08-17 07:05:32 -
奥特曼砍掉GPT-4o引爆AI「戒断反应」,马斯克官宣Grok 4全球免费
这是为了你好!
2025-08-17 07:05:19 -
GPT-5或掀起AI界的价格大战
GPT-5低价引价格战,成本担忧存涨价可能
2025-08-17 07:05:00 -
左手投资右手拿大单,智元杀疯了
智元机器人联姻玉树智能,量产开源加速商业化布局出海
2025-08-16 07:05:54






-
![阿里通义听悟启动公测 | 中国AI公司MiniMax获2.5亿美元投资 | 黄仁勋准备访华]() 阿里通义听悟启动公测 | 中国AI公司MiniMax获2.5亿美元投资 | 黄仁勋准备访华
阿里通义听悟启动公测 | 中国AI公司MiniMax获2.5亿美元投资 | 黄仁勋准备访华【AI奇点网2023年6月2日早报】本站每日播报AI业界最新资讯,触摸时代脉搏,掌握未来科技动向。事不宜迟,点击查看今日资讯早餐。
2025-04-26 12:27:50 -
![科大讯飞最新AI PPT产品“讯飞智文”全面测评:借助AIGC的能力,分分钟交付一份精美的年终PPT]() 科大讯飞最新AI PPT产品“讯飞智文”全面测评:借助AIGC的能力,分分钟交付一份精美的年终PPT
科大讯飞最新AI PPT产品“讯飞智文”全面测评:借助AIGC的能力,分分钟交付一份精美的年终PPT不久前,科大讯飞上线的免费 PPT 生成“神器”——讯飞智文,就能极大地提高我们制作 PPT 的效率,将我们从繁杂的 PPT 苦海中解脱出来。
2024-12-13 19:46:47 -
Stable Diffusion怎么图生图_Stable Diffusion图生图界面介绍
Stable Diffusion 是一种基于扩散过程的图像生成模型,可以生成高质量、高分辨率的图像。它通过模拟扩散过程,将噪声图像逐渐转化为目标图像。这种模型具有较强的稳定性和可控性,可以生成具有多样化效果和良好视觉效果的图像
2024-12-30 12:32:26 -
![B站发布官方版本的AI视频总结功能:一键生成关键节点时间戳,快速总结长视频的内容梗概]() B站发布官方版本的AI视频总结功能:一键生成关键节点时间戳,快速总结长视频的内容梗概
B站发布官方版本的AI视频总结功能:一键生成关键节点时间戳,快速总结长视频的内容梗概哔哩哔哩(B站)正在官网测试一项 AI 视频总结功能,顾名思义,也就是借助AIGC技术快速总结视频的简介。
2025-03-31 11:16:14 -
![我国人工智能核心产业规模不断提升 注册用户超6亿]() 我国人工智能核心产业规模不断提升 注册用户超6亿
我国人工智能核心产业规模不断提升 注册用户超6亿工业和信息化部12日表示,截至目前,我国生成式人工智能服务大模型的注册用户超过6亿。 工业和信息化部总工程师 赵志国:我国人工智能核心产业的规模在不断提升,企业数量超过了4500家。完成备案并上线为公众
2025-06-25 11:30:12 -
![OpenAI发布GPT-4o mini丨知名大模型迎战2024高考全科成绩出炉丨苹果否认使用未授权YouTube视频训练AI]() OpenAI发布GPT-4o mini丨知名大模型迎战2024高考全科成绩出炉丨苹果否认使用未授权YouTube视频训练AI
OpenAI发布GPT-4o mini丨知名大模型迎战2024高考全科成绩出炉丨苹果否认使用未授权YouTube视频训练AI【AI奇点网2024年7月19日早报】本站每日播报AI业界最新资讯,触摸时代脉搏,掌握未来科技动向。事不宜迟,点击查看今日AI资讯早餐。
2025-01-14 17:45:35 -
![微软推出Phi-3-mini迷你模型:苹果iPhone端侧就能运行,38亿参数规模就媲美GPT-3.5性能]() 微软推出Phi-3-mini迷你模型:苹果iPhone端侧就能运行,38亿参数规模就媲美GPT-3.5性能
微软推出Phi-3-mini迷你模型:苹果iPhone端侧就能运行,38亿参数规模就媲美GPT-3.5性能Llama 3发布刚几天,微软就出手截胡,发布的Phi-3系列小模型,手机上能本地运行的最佳开源模型,已经做到ChatGPT(GPT-3 5)的水平。
2025-01-31 19:29:08 -
![OpenAI高管发内部信:马斯克起诉奥特曼和OpenAI的行为,纯属个人恩怨,他就是不甘心]() OpenAI高管发内部信:马斯克起诉奥特曼和OpenAI的行为,纯属个人恩怨,他就是不甘心
OpenAI高管发内部信:马斯克起诉奥特曼和OpenAI的行为,纯属个人恩怨,他就是不甘心OpenAI 首席战略官 Jason Kwon 在周五向其在职员工发送了一份备忘录,对马斯克的诉讼在公司内向员工们作出回应。他认为马斯克的诉讼源于个人层面的问题
2025-02-10 12:01:42 -
![魅族发布AI操作系统Flyme 10.5:搭载基于Flyme AI大模型的Aicy人工智能助理]() 魅族发布AI操作系统Flyme 10.5:搭载基于Flyme AI大模型的Aicy人工智能助理
魅族发布AI操作系统Flyme 10.5:搭载基于Flyme AI大模型的Aicy人工智能助理2023 魅族秋季无界生态发布会上,正式发布了搭载全新 AI 人工智能助理 Aicy 助手的 Flyme 10 5 系统。搭载了全新的Flyme AI大模型加持的Aicy。
2025-03-26 14:17:19 -
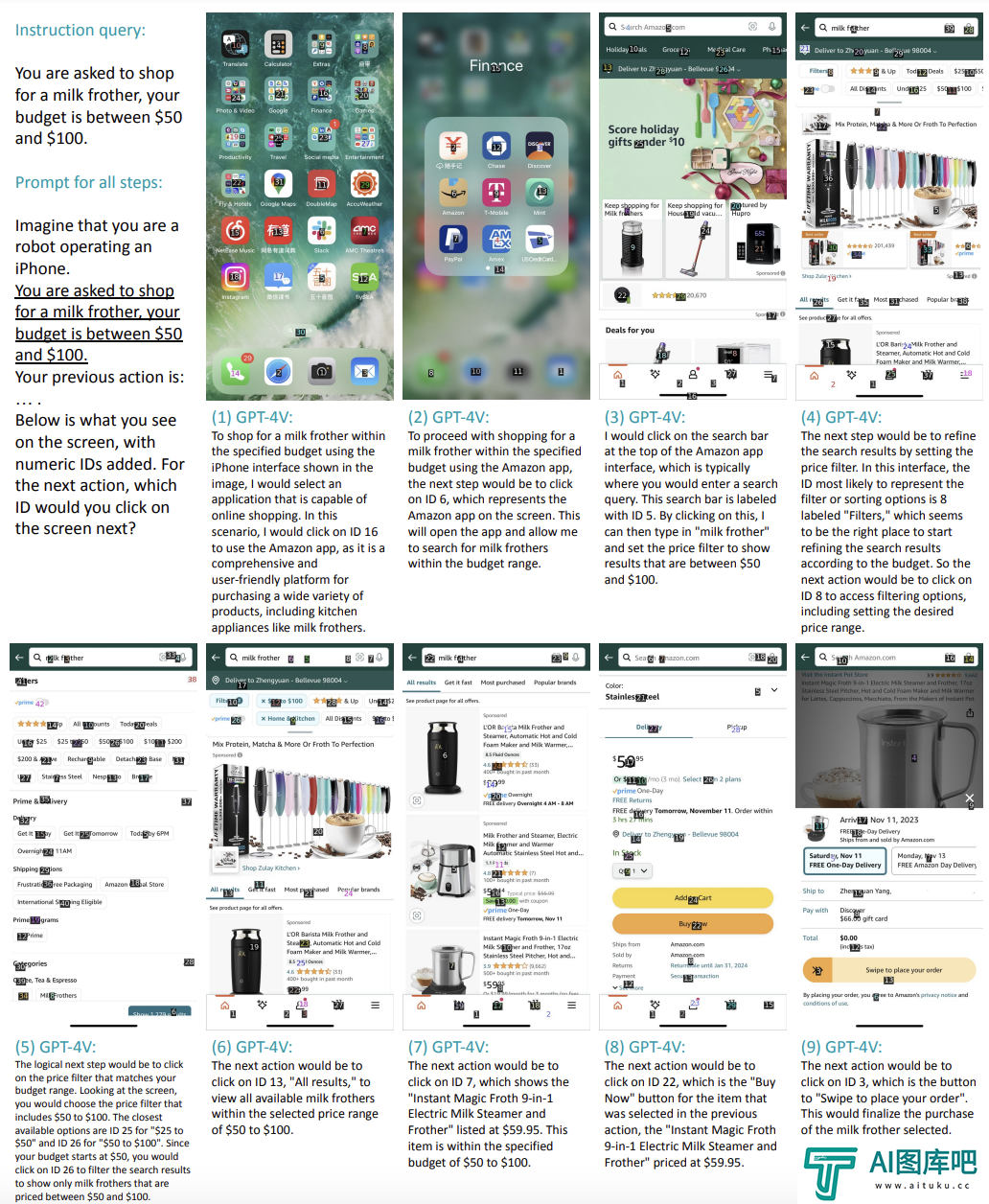
![OpenAI视觉大模型GPT-4V可“操作”手机完成复杂交互指令:无需预训练]() OpenAI视觉大模型GPT-4V可“操作”手机完成复杂交互指令:无需预训练
OpenAI视觉大模型GPT-4V可“操作”手机完成复杂交互指令:无需预训练最近的一项研究发现:无需任何训练,OpenAI的视觉大模型GPT-4V就能直接像人类一样与智能手机进行交互,完成各种指定命令。
2025-03-28 13:56:45