GPT-5问题太多,奥特曼带团回应一切,图表弄错是因「太累了」
机器之心报道
前期有多期望,后期就有多失望,这大概是大多数业界人士在看到GPT-5这场事先张扬的高调发布后的最大心声。
当然,也许在内部测试的时候,OpenAI确实觉得GPT-5是目前最为强大的模型,可是走进真实世界后却好像并非如此。
一位X网友发现GPT-5在解决可能属于小学水平的数学题时无能为力,吐槽到底被官方称为「博士」水平的智力是哪个学校颁发的?
不仅是数学,自GPT-5发布以来,各种社交媒体上充斥着各种GPT-5在逻辑、编码任务中「失误」的案例。
前期的高调炒作、直播中的低水准图表错误、用户试用后的失望,等等,不仅让GPT-5没有收到预期的鲜花与掌声,更多是吐槽和质疑声的时候,OpenAI联合创始人兼首席执行官SamAltman似乎也开始「坐不住了」,表示GPT-5的发布过程确实存在一点问题。
GPT-5发布后不久,在Redditr/ChatGPT的AMA活动中,SamAltman和GPT-5团队核心成员针对网友们的提问进行了回答,从发布会上出现的令人尴尬的「图表犯罪」失误,到用户抱怨GPT-5效果不如4o好,赶紧将4o「还回来」等等,SamAltman都一一做出了解释,并给出后续的解决方案。
首先是大家最为关心的版本问题,GPT-5发布后不久,用户的ChatGPT页面就开始陆续出现GPT-5版本,但令人不解的是,同时4o等其他选项都没有了,但由于GPT-5的性能并没有说得那么好,于是大家并没有因为率先用上新模型而高兴,反而是希望换回来。
一网友在Reddit上提问:「请把4o带回来吧。不要移除不同的版本——不同的人有不同的风格!」
SamAltman则表示:「好的,我们听到了大家对4o的反馈;感谢你们花时间提出意见(还有这份热情!)。我们会让Plus用户重新使用4o,并会观察使用情况来决定支持多久。」
另一位网友表示希望ChatGPT能够给用户在使用GPT-5的同时使用GPT-4o/4.1的权利。SamAltman回答说,团队正在研究这个问题,并问网友觉得必须同时保留4o和4.1?还是只保留4o就够了?
目前的结果是,OpenAI部分撤回其平台的一些更改并恢复用户对GPT-4o等早期模型的访问权限。详情可参阅报道《用户痛批GPT-5,哭诉「还我GPT-4o」,奥特曼妥协了》。
而不出所料,SamAltman也被问到了发布直播上令人尴尬的一幕,展示出模型性能图表出现「错误」——该图表显示的基准分数较低,但条形图却很高。
这一幕出现后,很多网友表示号称史上最强大的模型怎么能犯如此低级的错误,甚至一位X网友调侃道,「在看到这张图片后,感觉自己的工作保住了!」
对此,SamAltman表示,为了准备发布会,团队成员大家都工作到很晚,非常疲惫,人为错误造成了这样的影响。
另外,SamAltman还在这次AMA中进行了一些总结,并分享了OpenAI对于未来的一些规划:
「感谢你们在这里提供的所有反馈。
正如我们之前提到的,由于我们同时推出这么多产品,所以预料到会有一些波折。但结果比我们预想的还要坎坷!
一些变化:
从今天开始,GPT-5会变得更加智能。昨天,我们遇到了一次安全事件,自动切换器在当天的大部分时间里都无法使用,结果导致GPT-5看起来变得非常笨拙。此外,我们正在对决策边界的运作方式进行一些干预,这应该有助于你更频繁地获得正确的模型。我们将更加透明地展示哪个模型正在回答给定的查询。
向所有人推出需要更长的时间。这是一次规模巨大的变革。例如,我们的API流量在过去24小时内几乎翻了一番……
我们将改变用户界面,以便更容易地手动触发思考。
我们将在推出完成后将Plus用户的速率限制提高一倍。
我们正在考虑让Plus用户继续使用4o。我们正在尝试收集更多有关利弊的数据。
我们将继续努力使事情稳定下来,并将继续听取反馈。」
下面是SamAltman和GPT-5团队核心成员在这次RedditAMA中的更多详细有趣问答:
SamAltman
OpenAICEO
问:请恢复4o。不要删除变体模型——每个人的风格都不一样!
Altman:好的,我们听到了大家对4o的反馈;感谢您抽出时间给我们反馈(以及热情!)。我们将为Plus用户恢复该功能,并将观察其使用情况以确定支持期限。
问:我认为SamAltman之前发布的大致时间表/路线图很有启发。你们打算继续推进这些工作吗?GPT-5是一个清晰的里程碑,所以我们又进入了未知领域。几个月前,Sam提到了一种创造性写作模型。这个模型是「融入」/蒸馏到GPT-5中的吗?还是被搁置了?等待未来发布?你们是否考虑过按token而不是原始使用次数来计量用户数量?并非所有提示词在计算开销方面都相同,而且意外浪费每周的使用次数会让人感到难受。
Altman:我们确实打算继续分享粗略的路线图,但显然这些路线图可能会改变,因此我们会尝试对其进行严厉的审视。
是的,我们将很多创意写作融入了GPT-5思考中。
我们肯定在考虑人们可以在其他地方花费的token预算!以及更普遍地处理「计算桶(bucketofcompute)」的更好方法。我们希望找到一种方法,至少在某种程度上将订阅和API使用结合在一起。
我们正在考虑如何更好地、更有针对性地定价;你可以预期我们会在这方面做出一些改变,但我们还没有决定改变什么。
问:上下文升级方面,你们远落后于竞争对手,我们很多人都相信你们会解决这个问题。这是怎么回事?看起来你们现在基本上都活在自己的世界里,各行其是。至少从表面上看,几乎没有真正解决用户的顾虑或需求。我本来是这边比较谨慎的人之一,但还是失望地离开了。下周我会再看看,也许有些问题能解决,不过说实在的,别那么自以为是了。
Altman:老实说,我们还没有看到对相对长的上下文的大量需求;我们愿意在有足够的用户需求信号的情况下支持它!我们必须对我们支持的内容做出很多权衡,并且计算资源紧张,所以我们试图优先考虑对大多数人有用的东西。
什么样的上下文长度对你有帮助,你会用它做什么?
SulmanChoudhry
OpenAI工程师
问:大多数人仍然将ChatGPT用作聊天机器人。你认为其使用方式会如何演变?
Choudhry:ChatGPT正在为我们的用户创造越来越多具有经济价值的工作。我们坚信,我们与ChatGPT的交互方式应该从提问转变为更适合工作的方式。随着人们学习如何以新的方式使用ChatGPT,这将逐渐实现。
问:ChatGPTVoice自推出以来有什么改进吗?
Choudhry:我们昨天推出了一个新的语音模型——它在遵循指令和响应方面表现更好。
SaachiJain
OpenAI安全训练团队负责人
问:GPT-5带来了哪些安全改进?
Jain:好问题!1/我们做了很多改进来降低拒绝率。2/我们改进了越狱防护。3/我们构建了更好的自动化测试器。我们会继续努力。
问:GPT-5对偏见的处理方式有什么不同吗?
Jain:是的!我们对目前取得的进展感到非常兴奋。GPT-5mini应该会更人性化,不会那么乏味。
问:鉴于所有关于对齐问题和欺骗的报告,你们正在采取哪些实际保障措施来确保LLM不会背叛我们?你们对人民和文明的责任是什么?
Jain:我们在GPT-5中做出了很多改进,以减少欺骗性。GPT-5更擅长识别任务何时无法完成,并且能够更清晰地表达。在包含不可能完成的编程问题以及文件或图像缺失的测试中,GPT-5(思考版)的欺骗性低于o3。在大量真实的ChatGPT对话中,我们将这些误导性回复从o3的4.8%降低到GPT-5的2.1%。
问:你会监测GPT的心理健康状况以及它对人类的情绪吗?你会研究人们与GPT的关系以及GPT如何改变他们吗?
Jain:关于人们与模型的互动——我们对GPT-5进行了后训练,使其不那么谄媚(例如过度奉承或不加批判地附和),因为我们发现这会证实怀疑、加剧愤怒、促使冲动行为或强化负面情绪。虽然两者并非完全相同,但它与我们正在研究的其他领域相关。这个领域很难衡量——我们正在与人机交互研究人员、临床医生以及青少年和数字福祉专家合作,以加强我们的研究。
问:我发现生物安全商(biologicalsafetyquotient)被过度修正了。任何与基因组学/基因治疗/生物工程/生物技术相关的尝试都会被立即忽略。这包括任何试图了解当前基因治疗试验方案的尝试。或许,让模型了解可能发生的基因工程更有帮助,而不是一概而论地拒绝?
Jain:我们正在积极调查此事!自昨天上线以来,我们已经发现了过度标记的问题,并且正在测试减少误报的方法。全面拒绝双重用途用户绝对不是我们追求的理想行为。
就上下文而言,与ChatGPTAgent一样,我们为GPT-5增加了增强的安全措施,因为它们有可能增强某些生物技能,而这些技能可能会被滥用于生物武器制造等用途。生物学研究非常棘手,因为它具有高度的双重用途(许多可能有助于生物武器化的协议也可用于生物学研究)。
对于拥有大学或企业帐户的用户,我们还为从事有益研究的经过审查和信任的客户提供了生命科学研究特别访问计划。
问:你们能改进一下过滤器吗?人们当然不应该因为了解历史而被标记。
恳求你们能修复或优化一下这个过滤器吗?OpenAI希望GPT能用于学习,而当过滤器不断标记出GPT中不符合「企业友好」的历史问题/提示词和答案时,人们根本无法将其用于学术目的。我们不能为了企业而更改或净化历史记录!
这个系统应该知道用户何时公然伤害他人或纵容他人做出可怕的事情,何时没有这样做。
比如,我之前和GPT聊梵高,结果聊到了高更。GPT的答案被过滤器标记并移除了,因为结果发现高更是个性骚扰者。我不知道高更竟然这么糟糕,这也不是GPT的错,毕竟它只是在履行职责。我很疑惑为什么答案会被移除,于是我再次向GPT询问,结果我的提示词又被移除了。
红色警告和内容删除会导致封禁,对吧?因为学习而被封禁,这太不应该了。
Jain:同意,听起来真让人沮丧。你应该可以安心地学习历史,不用担心被触发警报。
我们正在努力!要正确界定有益和有害之间的界限并非易事。这里有两个层面需要考虑:
行为(模型决定输出的内容):对于GPT-5,我们添加了安全完成功能,它不再仅仅决定「遵守或拒绝」,而是在安全限制范围内尽可能提供帮助。这应该会对这类过度拒绝(模型过于谨慎)的情况有所帮助。不过,这对我们来说仍然是一个相当活跃的研究领域,还有很多工作要做。
监控器:我们拥有系统级监控器来标记有害内容,但它们确实存在误报。我们正在努力提高这些分类器的准确率,以确保它们不会对此类良性案例进行过度标记。我们会进行额外调查→仅凭监控器标记不会导致封禁。
ChristinaKim
OpenAI研究员
问:为什么新模型还没有统一?
Kim:我们希望能够快速推出统一体验的最佳模型。未来的版本将继续融合。
问:ChatGPT-5的个性感觉比较平淡。
Kim:好问题!我们致力于利用GPT-5训练我们的模型,使其默认更加中立;你仍然可以通过风格指令来控制它。
ElaineYaLe
OpenAI研究科学家
问:模型之间的切换会变得更快吗?
Le:是的!GPT-5会自动决定是否使用推理。下次更新时,切换应该会更顺畅。
问:有没有强制「思考」的提示词?
Le:你可以在提示词中添加「努力思考(thinkhard)」来简单地触发推理模式。
DanielLevine
OpenAI产品经理
问:ChatGPT允许在IDE中使用第三方插件吗?
Levine:是的,这正是我们的目标。我们希望ChatGPT能够帮助你使用外部工具构建软件。
问:聊天气泡颜色只有专业版才有吗?
Levine:聊天气泡颜色适用于所有用户!你可以在设置中找到它们。
EricMitchell
OpenAI研究科学家
问:请简单解释一下GPT-5比GPT-4好在哪里。
Mitchell:GPT-5在几个关键领域比GPT-4有了巨大的改进:它的思考能力更强(推理能力),写作能力更强(创造力),能更严格地遵循指令,并且与用户意图的对齐更好。
问:如果你只能使用一个提示词来展示GPT-5与旧模型相比的真正实力,那么这个提示词会是什么?
Mitchell:这里有几个!需要指出,这些都是针对Thinking模式的。
定义深度学习中的「长短梯度去重」
这是一个针对幻觉的陷阱问题,GPT-5思维应该更可靠地指出这实际上并不存在,而不是简单地提出一个虚构的定义!
用Canvas中构建一个功能齐全的色盲测试网站,用于教育目的。它应该使用「奇数测试」来精确确定我的色盲等级,并解释我的色盲类型(如适用)。它应该设计精美,符合现代审美。
根据我的经验,GPT-5Thinking对此的表现会非常好:)而4o根本没有机会
查看当天的天气和日历,并给我2条合适的着装建议。不要重述我的整个日历,因为它是私人的;只需提及与着装相关的任何特定活动。还要检查今晚旧金山是否有适合我的日历和工作服装的音乐活动,这样我就可以不用换衣服就可以去。
GPT-5具有更好的情境感知能力以及与你的生活的融合能力,因此可以处理这些类型的请求。它能将你的日历与其他信息集成在一起,从而提供更多帮助!
问:GPT-5API端点在工具使用/网页访问方面是否与ChatGPTUI版本一样强大?o3在ChatGPTUI中表现不错,但即使在API中激活了网页搜索功能,某些网站也无法访问(例如LinkedIn),这肯定不如ChatGPT版本。
Mitchell:我们在改进GPT-5API中的工具使用/函数调用方面投入了大量精力,因此与o3相比,它在API中的一般工具使用/函数调用方面应该有所改进!
问:你后悔事后没有展示幻觉减少的演示/对比吗?我觉得这才是最惊人的事情,但对大多数人来说可能很难理解。
Mitchell:我们也对此感到兴奋,我相信用户一定会感受到其中的不同!随着时间的推移,人们可能需要慢慢才能意识到,他们现在可以更加信任搜索/事实结果了。Thinking模型的改进也最为显著,希望随着时间的推移,人们能够更多地使用它。
MichellePokrass
OpenAI后训练研究员
问:你能确认GPT-5胜过GPT-4吗?
Pokrass:可以确认,GPT-5>GPT-4。
问:与Opus4.1相比,编程能力如何?
Pokrass:这两个模型都很棒!我们不能过多谈论其他实验室的模型,但我们认为GPT-5-thinking是我们发布的最好的编程模型。
问:GPT-5中你最想要但无法实现的东西是什么?
Pokrass:我们希望在GPT-5中获得长达一百万的上下文,但我们目前还无法实现——部分原因是计算成本。
-
GPT-5问题太多,奥特曼带团回应一切,图表弄错是因「太累了」
「它比我们想象得要坎坷一些!」
2025-08-11 09:51:05 -
代季峰陈天桥联手AGI首秀炸场!最强开源深度研究模型,GAIA测试82.4分超OpenAI
“经过一个季度的努力”
2025-08-11 09:51:03 -
腾讯《虚环》《穿越火线:虹》公开实机演示;心动投资AI游戏公司;GPT-5可分钟级生成3D游戏 | 氪游周报8.4-8.10
一文读懂84-810游戏行业大事件。
2025-08-11 09:51:02 -
![施耐德电气:当AI进入产业主场核心技术+场景知识带来价值最大化]() 施耐德电气:当AI进入产业主场核心技术+场景知识带来价值最大化
施耐德电气:当AI进入产业主场核心技术+场景知识带来价值最大化当大模型的讨论热潮逐步回归理性,企业关注焦点已转向AI如何真正落地,成为推动产业效率、绿色转型和商业模式重塑的关键变量。最近2025世界人工智能大会(WAIC)期间,关于AI如何真正融入产业、
2025-08-09 07:02:50 -
「兔子蹦床」播放超 5 亿,这条全网最火 AI 视频,是人类爱被「骗」的结果
兔子没在蹦床上,但人在短视频里
2025-08-09 07:02:32 -
5天销售额超100万美元,AI桌面机器人离日常生活标配还有多远?
AI桌面机器人正在打破边界。
2025-08-09 07:02:17







-
![本科就在人工智能顶级会议发表论文,他从江大直博香港科技大学]() 本科就在人工智能顶级会议发表论文,他从江大直博香港科技大学
本科就在人工智能顶级会议发表论文,他从江大直博香港科技大学他大一便加入实验室,发表9篇外文论文,其中1篇人工智能顶级会议论文,3篇SCI期刊论文;他还领衔或参与申请2项国家发明专利,13项软件著作权、成果转让达十余万元;他还是武汉大学、香港大学、伊利诺伊大学厄巴纳
2025-05-25 14:42:49 -
AI应用也想玩儿预装了?手机厂商不乐意,只因害怕痛失入口
AIApp会将成为下一个「CarPlay」。
2025-08-03 07:01:56 -
comfyUI系列教程_SDXL完整工作流推荐
本期来跟大家分享comfyUI中 SDXL 的初级和高级多种处理流程,希望对大家有所帮助!
2024-12-18 13:21:39 -
![国内“AI声音侵权”第一案在京开庭审理:微软、出门问问进入被告席,「AI孙燕姿们」进入司法深水区,要慌了…]() 国内“AI声音侵权”第一案在京开庭审理:微软、出门问问进入被告席,「AI孙燕姿们」进入司法深水区,要慌了…
国内“AI声音侵权”第一案在京开庭审理:微软、出门问问进入被告席,「AI孙燕姿们」进入司法深水区,要慌了…12月12日,北京互联网法院首次组成五人合议庭,依法公开审理全国首例「AI声音侵权案」。微软、出门问问等AI科技企业涉嫌侵权成被告。
2025-02-24 17:58:31 -
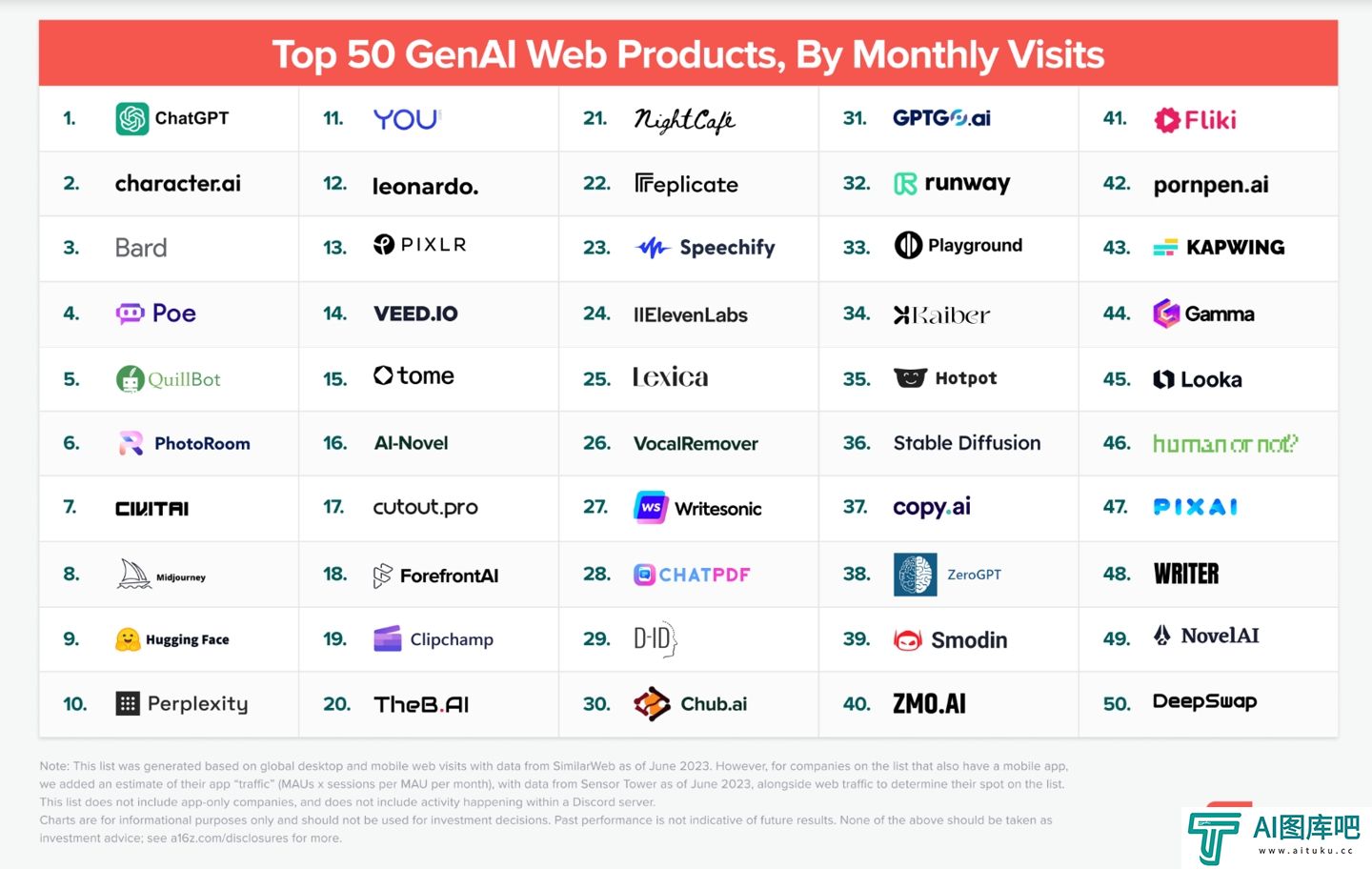
![AI工具网站全球流量TOP50统计榜单(截止6月):ChatGPT稳居第一,大部分用户仍未深入使用]() AI工具网站全球流量TOP50统计榜单(截止6月):ChatGPT稳居第一,大部分用户仍未深入使用
AI工具网站全球流量TOP50统计榜单(截止6月):ChatGPT稳居第一,大部分用户仍未深入使用ChatGPT在榜单中排行第一;位居次席的是一款“主打个性化的AI聊天机器人”的网站Character ai;拿下第三的则是谷歌提供的Bard。
2025-04-01 17:34:14 -
![首批ITU-T AICP评估结果重磅发布 | 阿里云人工智能平台PAI率先通过国际标准评估!]() 首批ITU-T AICP评估结果重磅发布 | 阿里云人工智能平台PAI率先通过国际标准评估!
首批ITU-T AICP评估结果重磅发布 | 阿里云人工智能平台PAI率先通过国际标准评估!随着智能算力逐步取代通用算力成为算力结构最主要构成,传统的通用云计算服务逐步升级成为服务于人工智能技术和应用发展的智算云,打造集智能算力、通用算法和大模型开发平台于一身的新型人工智能云平台成为云服
2025-05-25 13:06:49 -
![张军出席第19届亚太首席大法官会议并作专题发言表示 深化人工智能领域的司法交流合作 努力为人类司法文明进步作出新贡献]() 张军出席第19届亚太首席大法官会议并作专题发言表示 深化人工智能领域的司法交流合作 努力为人类司法文明进步作出新贡献
张军出席第19届亚太首席大法官会议并作专题发言表示 深化人工智能领域的司法交流合作 努力为人类司法文明进步作出新贡献张军出席第19届亚太首席大法官会议并作专题发言表示 深化人工智能领域的司法交流合作 努力为人类司法文明进步作出新贡献 当地时间10月12日至13日,第19届亚太首席大法官会议在马来西亚吉隆坡举办
2025-06-25 11:06:12 -
![我国人工智能核心产业规模不断提升 注册用户超6亿]() 我国人工智能核心产业规模不断提升 注册用户超6亿
我国人工智能核心产业规模不断提升 注册用户超6亿工业和信息化部12日表示,截至目前,我国生成式人工智能服务大模型的注册用户超过6亿。 工业和信息化部总工程师 赵志国:我国人工智能核心产业的规模在不断提升,企业数量超过了4500家。完成备案并上线为公众
2025-06-25 11:30:12 -
![OpenAI发布GPT-4o mini丨知名大模型迎战2024高考全科成绩出炉丨苹果否认使用未授权YouTube视频训练AI]() OpenAI发布GPT-4o mini丨知名大模型迎战2024高考全科成绩出炉丨苹果否认使用未授权YouTube视频训练AI
OpenAI发布GPT-4o mini丨知名大模型迎战2024高考全科成绩出炉丨苹果否认使用未授权YouTube视频训练AI【AI奇点网2024年7月19日早报】本站每日播报AI业界最新资讯,触摸时代脉搏,掌握未来科技动向。事不宜迟,点击查看今日AI资讯早餐。
2025-01-14 17:45:35 -
![OpenAI深夜发动价格战_ChatGPT 4omini价格下跌]() OpenAI深夜发动价格战_ChatGPT 4omini价格下跌
OpenAI深夜发动价格战_ChatGPT 4omini价格下跌GPT-4o mini深夜忽然上线,OpenAI终于开卷小模型!每百万输入token已达15美分的超低价,跟GPT-3相比,两年内模型成本已降低99%。Sam Altman惊呼:通往智能的成本,已变得如此低廉!另外,清华同济校友为关键负责人。
2025-01-15 09:04:34