基于DiT,支持4K图像生成,华为诺亚0.6B文生图模型PixArt-Σ来了
本文转载自机器之心
众所周知,开发顶级的文生图(T2I)模型需要大量资源,因此资源有限的个人研究者基本都不可能承担得起,这也成为了AIGC(人工智能内容生成)社区创新的一大阻碍。同时随着时间的推移,AIGC 社区又能获得持续更新的、更高质量的数据集和更先进的算法。
于是关键的问题来了:我们能以怎样的方式将这些新元素高效地整合进现有模型,依托有限的资源让模型变得更强大?
为了探索这个问题,华为诺亚方舟实验室等研究机构的一个研究团队提出一种新的训练方法:由弱到强式训练(weak-to-strong training)。

论文标题:PixArt-Σ: Weak-to-Strong Training of Diffusion Transformer for 4K Text-to-Image Generation
论文地址:https://arxiv.org/pdf/2403.04692.pdf
项目页面:https://pixart-alpha.github.io/PixArt-sigma-project/
他们的研究基于他们去年十月提出的一种高效的文生图训练方法 PixArt-α,参阅机器之心报道《超低训练成本文生图模型 PixArt 来了,效果媲美 MJ,只需 SD 10% 训练时间》。PixArt-α 是 DiT(扩散 Transformer)框架的一种早期尝试。而现在,随着 Sora 登上热搜以及 Stable Diffusion 层出不穷的应用,DiT 架构的有效性得到了研究社区越来越多工作的验证,例如 PixArt, Dit-3D, GenTron 等「1」。
该团队使用 PixArt-α 的预训练基础模型,通过整合高级元素以促进其持续提升,最终得到了一个更加强大的模型 PixArt-Σ。图 1 展示了一些生成结果示例。

PixArt-Σ 如何炼成?
具体来说,为了实现由弱到强式训练,造出 PixArt-Σ,该团队采用了以下改进措施。
更高质量的训练数据
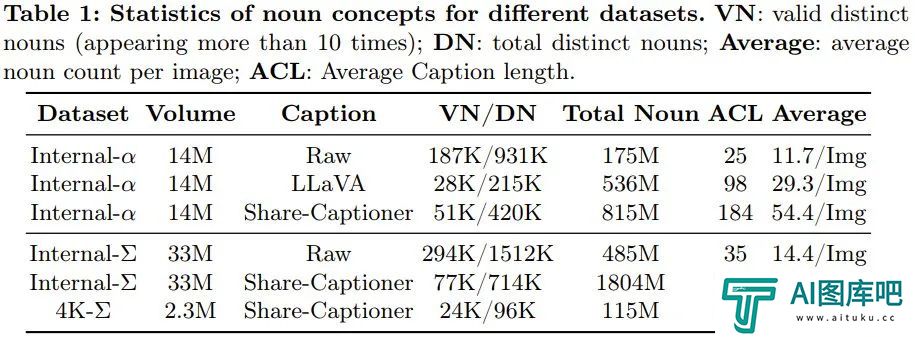
该团队收集了一个高质量数据集 Internal-Σ,其主要关注两个方面:
(1) 高质量图像:该数据集包含 3300 万张来自互联网的高分辨率图像,全都超过 1K 分辨率,包括 230 万张分辨率大约为 4K 的图像。这些图像的主要特点是美观度高并且涵盖广泛的艺术风格。
(2) 密集且准确的描述:为了给上述图像提供更精准和详细的描述,该团队将 PixArt-α 中使用的 LLaVA 替换成了一种更强大的图像描述器 Share-Captioner。
不仅如此,为了提升模型对齐文本概念和视觉概念的能力,该团队将文本编码器(即 Flan-T5)的 token 长度扩展到了大约 300 词。他们观察到,这些改进可以有效消除模型产生幻觉的倾向,实现更高质量的文本 - 图像对齐。
下表 1 展示了不同数据集的统计数据。
高效的 token 压缩
为了增强 PixArt-α,该团队将其生成分辨率从 1K 提升到了 4K。为了生成超高分辨率(如 2K/4K)的图像,token 数量会大幅增长,这就会导致计算需求大幅增长。
为了解决这一难题,他们引入了一种专门针对 DiT 框架调整过的自注意力模块,其中使用了键和值 token 压缩。具体来说,他们使用了步长为 2 的分组卷积来执行键和值的局部聚合,如下图 7 所示。
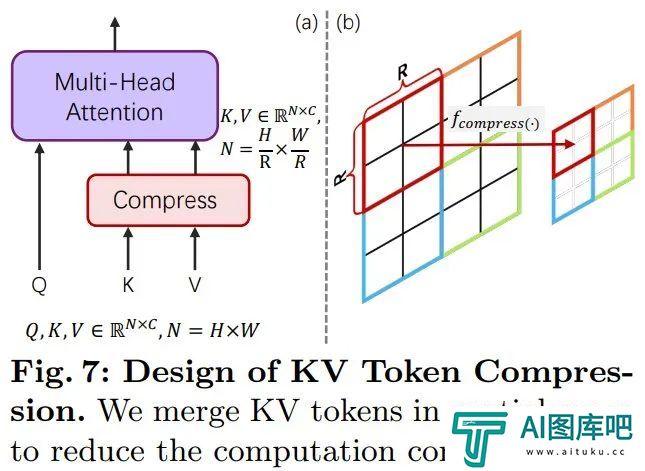
此外,该团队还采用了一种专门设计的权重初始化方案,可在不使用 KV(键 - 值)压缩的前提下从预训练模型实现平滑适应。这一设计可有效将高分辨率图像生成的训练和推理时间降低大约 34%。
由弱到强式训练策略
该团队提出了多种微调技术,可快速高效地将弱模型调整为强模型。其中包括:
(1) 替换使用了一种更强大的变分自动编码器(VAE):将 PixArt-α 的 VAE 替换成了 SDXL 的 VAE。
(2) 从低分辨率到高分辨率扩展,这个过程为了应对性能下降的问题,他们使用了位置嵌入(PE)插值方法。
(3) 从不使用 KV 压缩的模型演进为使用 KV 压缩的模型。
实验结果验证了由弱到强式训练方法的可行性和有效性。
通过上述改进,PixArt-Σ 能以尽可能低的训练成本和尽可能少的模型参数生成高质量的 4K 分辨率图像。
具体来说,通过从一个已经预训练的模型开始微调,该团队仅额外使用 PixArt-α 所需的 9% 的 GPU 时间,就得到了能生成 1K 高分辨率图像的模型。如此表现非常出色,因为其中还替换使用了新的训练数据和更强大的 VAE。
此外,PixArt-Σ 的参数量也只有 0.6B,相较之下,SDXL 和 SD Cascade 的参数量分别为 2.6B 和 5.1B。
PixArt-Σ 生成的图像的美观程度足以比肩当前最顶级的文生图产品,比如 DALL・E 3 和 MJV6.此外,PixArt-Σ 还展现出了与文本 prompt 细粒度对齐的卓越能力。
图 2 展示了一张 PixArt-Σ 生成 4K 高分辨率图像的结果,可以看到生成结果很好地遵从了复杂且信息密集的文本指令。

实验
实现细节
训练细节:对于执行条件特征提取的文本编码器,该团队按照 Imagen 和 PixArt-α 的做法使用了 T5 的编码器(即 Flan-T5-XXL)。基础扩散模型就是 PixArt-α。不同于大多数研究提取固定的 77 个文本 token 的做法,这里将文本 token 的长度从 PixArt-α 的 120 提升到了 300.因为 Internal-Σ 中整理的描述信息更加密集,可以提供高细粒度的细节。另外 VAE 使用了来自 SDXL 的已预训练的冻结版 VAE。其它实现细节与 PixArt-α 一样。
模型是基于 PixArt-α 的 256px 预训练检查点开始微调的,并使用了位置嵌入插值技术。
最终的模型(包括 1K 分辨率)是在 32 块 V100 GPU 上训练的。他们还额外使用了 16 块 A100 GPU 来训练 2K 和 4K 图像生成模型。
评估指标:为了更好地展示美观度和语义能力,该团队收集了 3 万对高质量文本 - 图像,以对最强大的文生图模型进行基准评估。这里主要是通过人类和 AI 偏好来评估 PixArt-Σ,因为 FID 指标可能无法适当地反映生成质量。
性能比较
图像质量评估:该团队定性地比较了 PixArt-Σ 与闭源文生图(T2I)产品和开源模型的生成质量。如图 3 所示,相比于开源模型 SDXL 和该团队之前的 PixArt-α,PixArt-Σ 生成的人像的真实感更高,并且也有更好的语义分析能力。与 SDXL 相比,PixArt-Σ 能更好地遵从用户指令。

PixArt-Σ 不仅优于开源模型,而且与当前的闭源产品相比也颇具竞争力,如图 4 所示。

生成高分辨率图像:新方法可以直接生成 4K 分辨率的图像,而无需任何后处理。此外,PixArt-Σ 也能准确遵从用户提供的复杂和详细的长文本。因此,用户无需费心去设计 prompt 也能得到让人满意的结果。
人类 / AI(GPT-4V)偏好研究:该团队也研究了人类和 AI 对生成结果的偏好。他们收集了 6 个开源模型的生成结果,包括 PixArt-α、PixArt-Σ、SD1.5、Stable Turbo、Stable XL、Stable Cascade 和 Playground-V2.0.他们开发了一个网站,可通过展现 prompt 和对应的图像来收集人类偏好反馈。
人类评估者可根据生成质量以及与 prompt 的匹配程度来给图像排名。结果见图 9 的蓝色条形图。
可以看出人类评估者对 PixArt-Σ 的喜爱胜过其它 6 个生成器。相比于之前的文生图扩散模型,如 SDXL(2.6B 参数)和 SD Cascade(5.1B 参数),PixArt-Σ 能以少得多的参数(0.6B)生成质量更高且更符合用户 prompt 的图像。
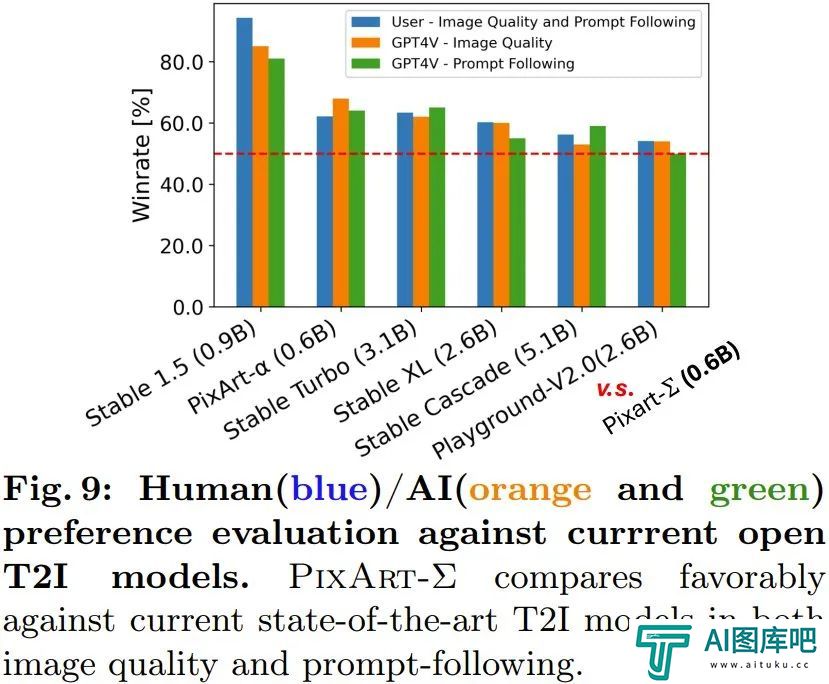
此外,该团队还使用了先进的多模态模型 GPT-4 Vision 来执行 AI 偏好研究。他们的做法是给 GPT-4 Vision 提供两张图像,让它基于图像质量和图像 - 文本对齐程度进行投票。结果见图 9 中的橙色和绿色条形图,可以看到情况与人类评估基本一致。
该团队也进行了消融研究来验证各种改进措施的有效性。更多详情,请访问原论文。
-
![基于DiT,支持4K图像生成,华为诺亚0.6B文生图模型PixArt-Σ来了]() 基于DiT,支持4K图像生成,华为诺亚0.6B文生图模型PixArt-Σ来了
基于DiT,支持4K图像生成,华为诺亚0.6B文生图模型PixArt-Σ来了华为诺亚0 6B文生图模型PixArt-Σ,采用了sora一样的Dit模型
2025-02-08 11:33:33 -
![ChatGPT每天耗费的电力相当于1.7万个美国家庭,AI vs人力投入产出比怎么算?网友:算完发现挺值!]() ChatGPT每天耗费的电力相当于1.7万个美国家庭,AI vs人力投入产出比怎么算?网友:算完发现挺值!
ChatGPT每天耗费的电力相当于1.7万个美国家庭,AI vs人力投入产出比怎么算?网友:算完发现挺值!ChatGPT居然这么费电?最新的等式出现了:ChatGPT日耗电量≈1 7万家庭日耗电量。什么概念?一年光电费就要花2亿!美国普通家庭平均单日用电29千瓦时,而ChatGPT的单日用电量超过了50万千瓦时。(美国商业用电一度约为0 147美元也就是1 06元,相当于一天53万元)消息一出就直接冲上热搜第一了。
2025-02-08 11:08:40 -
![「OpenAI宫斗」大男主奥特曼,赢麻了:内部调查宣告无罪,董事会的反对派全部背锅]() 「OpenAI宫斗」大男主奥特曼,赢麻了:内部调查宣告无罪,董事会的反对派全部背锅
「OpenAI宫斗」大男主奥特曼,赢麻了:内部调查宣告无罪,董事会的反对派全部背锅今天,OpenAI在官网公布了针对CEO奥特曼被罢免的调查结果,调查律师团给出的结论,令OpenAI董事会最终放心表态:「对奥特曼继续领导OpenAI充满信心。」
2025-02-08 10:45:47 -
![OpenAI奥特曼、英伟达黄仁勋预测:通用人工智能AGI五年内降临,可代替95%人类工作]() OpenAI奥特曼、英伟达黄仁勋预测:通用人工智能AGI五年内降临,可代替95%人类工作
OpenAI奥特曼、英伟达黄仁勋预测:通用人工智能AGI五年内降临,可代替95%人类工作Claude 3、Sora纷纷出现,还有万众期待的GPT-5,让所有人都不约而同地隐隐感觉:AGI似乎越来越近了。OpenAI奥特曼坚定地认为,AGI将在5年内实现。
2025-02-08 10:22:53 -
![面对Sora训练数据来源一问三不知!OpenAI遭遇成立以来最为惨烈的公关灾难]() 面对Sora训练数据来源一问三不知!OpenAI遭遇成立以来最为惨烈的公关灾难
面对Sora训练数据来源一问三不知!OpenAI遭遇成立以来最为惨烈的公关灾难《洛杉矶时报》科技专栏作家Brian Merchant尖锐批评Murati的表现:「作为OpenAI的CTO如此表现,要么是对自己公司的产品惊人的无知,要么就是在谎言!」
2025-02-08 09:57:24 -
![以身作则兑现开源承诺:马斯克宣布xAI公司本周内开源Grok AI大模型]() 以身作则兑现开源承诺:马斯克宣布xAI公司本周内开源Grok AI大模型
以身作则兑现开源承诺:马斯克宣布xAI公司本周内开源Grok AI大模型马斯克通过推特(X)平台宣布,自家人工智能研究公司 xAI,计划在本周内开源人工智能助手 Grok。
2025-02-07 17:44:49











-
![怎么快速给模特换装_怎么用stable diffusion给模特换装]() 怎么快速给模特换装_怎么用stable diffusion给模特换装
怎么快速给模特换装_怎么用stable diffusion给模特换装本篇教程主要运用StableDiffusion这个工具来进行操作,下面会通过几个小案例,给大家展示不同需求下,我们该如何使用StableDiffusion来辅助我们完成服装效果展示。本教程适用于电商设计场景、摄影场景等多个运用人物设计的实战中
2024-12-23 13:57:15 -
![万万没想到,兵马俑都开始跳「科目三」:阿里云通义千问APP打造“全民舞王”视频创作工具,实测效果大赞]() 万万没想到,兵马俑都开始跳「科目三」:阿里云通义千问APP打造“全民舞王”视频创作工具,实测效果大赞
万万没想到,兵马俑都开始跳「科目三」:阿里云通义千问APP打造“全民舞王”视频创作工具,实测效果大赞兵马俑跳《科目三》,是我万万没想到的。有人借助了阿里云之前走红的AI视频生成技术——「Animate Anyone」,生成出来了这个舞蹈片段。
2024-12-13 16:46:26 -
![stable diffusion初识_stable diffusion跟其他工具有什么区别]]() stable diffusion初识_stable diffusion跟其他工具有什么区别]
stable diffusion初识_stable diffusion跟其他工具有什么区别]关于Stable Diffusion的内容很多,在本篇教程里,我会先为你介绍Stable Diffusion模型的运行原理、发展历程和相较于其他AI绘图应用的区别。
2024-12-24 13:45:31 -
![如何使用 ChatGPT 调试代码]() 如何使用 ChatGPT 调试代码
如何使用 ChatGPT 调试代码当您的代码出现问题时,您可以向 ChatGPT 提供故障代码和问题描述。AI 工具将尝试识别并纠正问题。
2024-12-31 12:01:41 -
![怎么设置关键词权重_怎么设置Multi Prompts]() 怎么设置关键词权重_怎么设置Multi Prompts
怎么设置关键词权重_怎么设置Multi PromptsAI 绘画,顾名思义就是利用人工智能进行绘画,是人工智能生成内容(AIGC)的一个应用场景。其主要原理简单来说就是收集大量已有作品数据,通过算法对它们进行解析,最后再生成新作品,Midjourney是一个由同名研究实验室开发的人工智能程序。
2025-01-03 10:00:57 -
![零基础2天速成!白嫖「秋叶」官方AI绘画课程,卷死同事]() 零基础2天速成!白嫖「秋叶」官方AI绘画课程,卷死同事
零基础2天速成!白嫖「秋叶」官方AI绘画课程,卷死同事和「秋叶」一起学AI绘画,掌握Stable Diffusion、Midjourney的使用方法,开展AI绘画副业,搞钱!?
2024-12-17 12:53:01 -
思维脑图工具也能创作AI绘画作品,如何使用博思白板进行AI绘画
博思白板boardmix的创作平台提供多种登录方式,最方便要属直接微信扫码登录,然后绑定手机号实名制。再点击页面正中央紫色的按钮「免费使用」,你就可以进入博思白板boardmix的内容创作操作台。
2024-12-26 09:08:34 -
![AI绘图模型测评_Meta Imagine发布_Meta Imagine最新地址]() AI绘图模型测评_Meta Imagine发布_Meta Imagine最新地址
AI绘图模型测评_Meta Imagine发布_Meta Imagine最新地址针对Meta Imagine,Midjourney,Adobe Firefly,Dalle,这四个我心目中的比较大的AI绘图模型测评。我会从细节质量、审美(构图色彩等)、风格多样化、语义理解这四个维度来评测,每个维度3个Prompt,同时每个Prompt我会在AI绘图模型中roll3次,取效果最具有代表性的那个图,尽量减少偏见。
2024-12-13 17:44:01 -
![Midjourney角色一致性命令 "cref "测评丨如何保持多个角色一致性]() Midjourney角色一致性命令 "cref "测评丨如何保持多个角色一致性
Midjourney角色一致性命令 "cref "测评丨如何保持多个角色一致性预告了好久的MJ角色一致性功能终于来了, 新的命令“ --cref ”与 样式参考 “--sref”功能类似,但它不是匹配参考样式,而是尝试让角色匹配 "角色参考 "图像,--cref 目前只适用于 niji 6 和 v6 模型。
2024-12-13 18:32:59 -
![二次元界欢呼,动漫风格神级工具更新丨AI绘图Niji V6全面上手评测]() 二次元界欢呼,动漫风格神级工具更新丨AI绘图Niji V6全面上手评测
二次元界欢呼,动漫风格神级工具更新丨AI绘图Niji V6全面上手评测Niji V6正式更新,这期评测,我会在有限时间范围内,尽可能全面、客观的给大家展示并对比Niji V5与Niji V6的差异。整体我会分为几个维度来对比,分别是:创造力、角色张力、动漫风格表现、3D风格表现、其他风格表现
2024-12-13 19:56:45

![stable diffusion初识_stable diffusion跟其他工具有什么区别]](http://www.aituku.cc/uploadfile/2024/1224/d3a1bbf8bad6e281f82a2168727dfba1.png)