AI大模型“读懂”4K超清图像!上海AI Lab、香港中文大学联合打造多模态大模型:可自动分析网页海报内容
一个可以自动分析PDF、网页、海报、Excel图表内容的大模型,对于打工人来说简直不要太方便。
上海AI Lab,香港中文大学等研究机构提出的InternLM-XComposer2-4KHD(简写为IXC2-4KHD)模型让这成为了现实。

相比于其他多模态大模型不超过1500x1500的分辨率限制,该工作将多模态大模型的最大输入图像提升到超过4K (3840 x1600)分辨率,并支持任意长宽比和336像素~4K动态分辨率变化。
发布三天,该模型就登顶Hugging Face视觉问答模型热度榜单第一。
轻松拿捏4K图像理解
先来看效果~
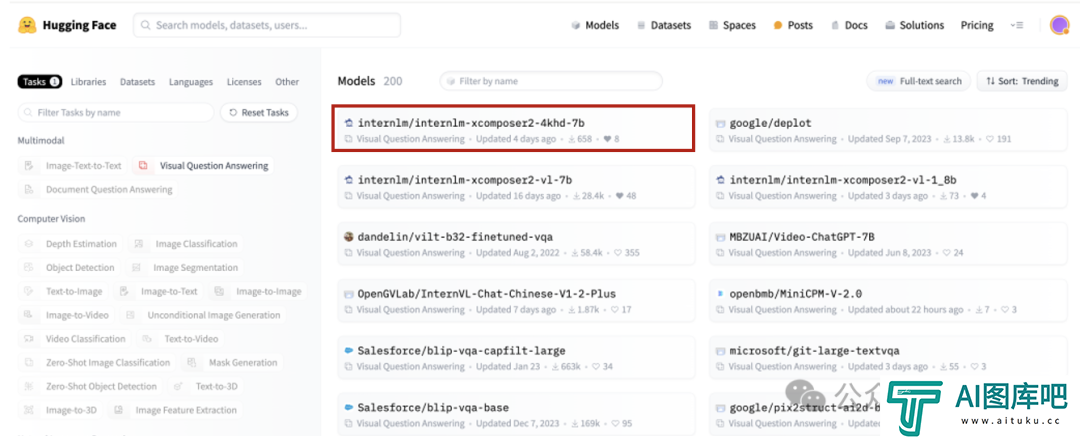
研究人员输入论文《ShareGPT4V: Improving Large Multi-Modal Models with Better Captions》的首页截图,分辨率高达2550x3300,并询问论文哪个模型在MMBench上的性能最高。
需要注意的是,该信息在输入截图的正文文字部分并未提及,仅仅出现在一个相当复杂的雷达图中。面对这么刁钻的问题,IXC2-4KHD成功理解了雷达图中的信息,正确回答问题。
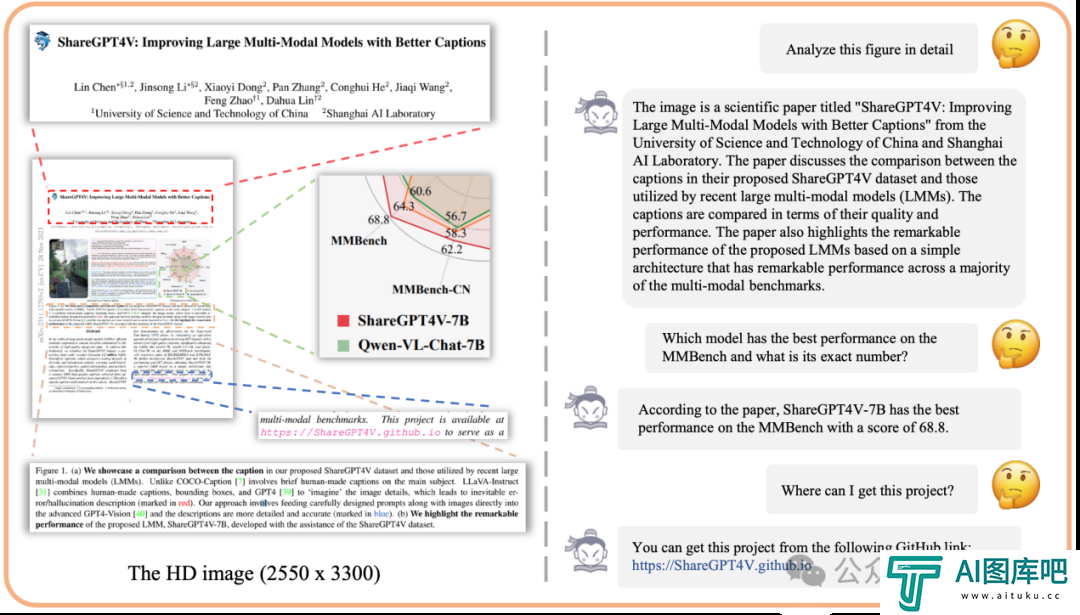
面对更加极端分辨率的图像输入816 x 5133,IXC2-4KHD轻松理解图像包括7个部分,并准确说明了每个部分包含的文字信息内容。

随后,研究人员还在16项多模态大模型评测指标上全面测试了IXC2-4KHD的能力,其中5项评测(DocVQA、ChartQA、InfographicVQA、TextVQA、OCRBench)关注模型的高分辨率图像理解能力。
仅仅使用7B参数量,IXC2-4KHD在其中10项评测取得了媲美甚至超越GPT4V和Gemini Pro的结果,展现了不局限于高分辨率图像理解,而是对各种任务和场景的泛用能力。
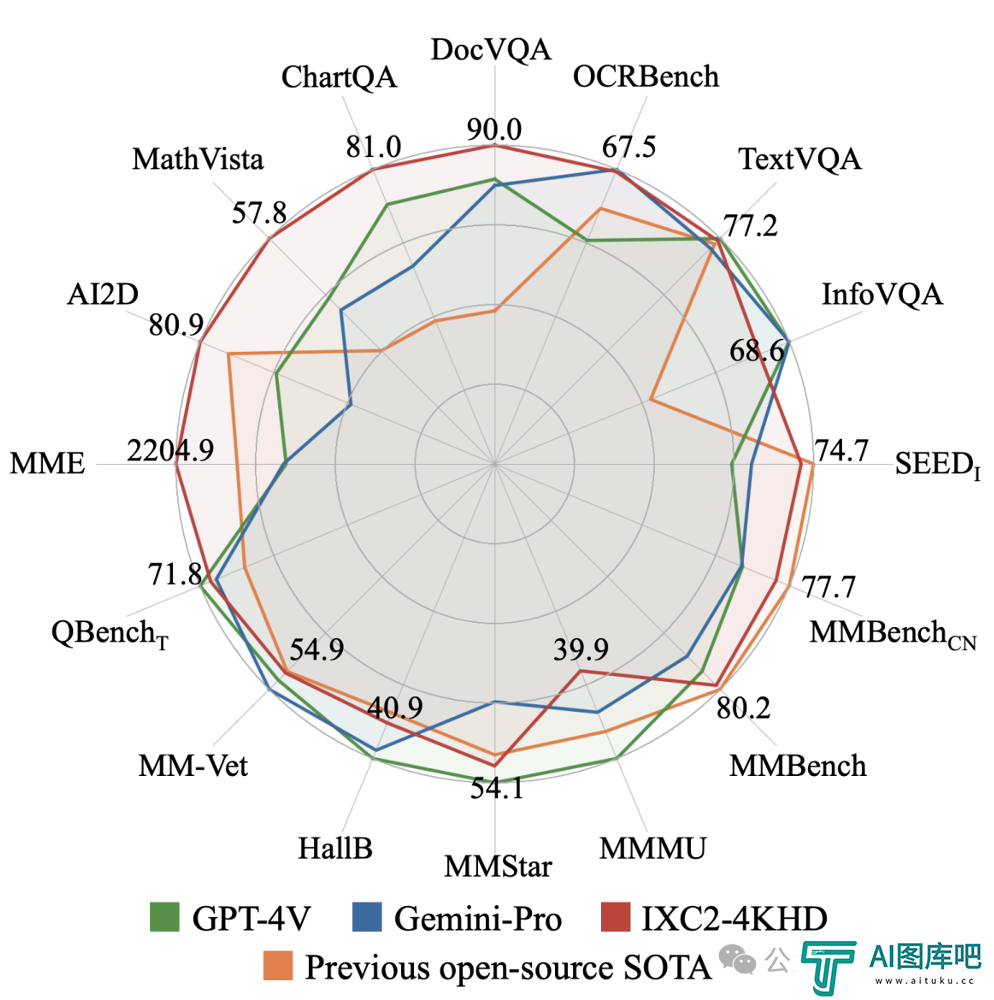
△仅7B参数量的IXC2-4KHD性能媲美GPT-4V和Gemini-Pro
如何实现4K动态分辨率?
为了实现4K动态分辨率的目标,IXC2-4KHD包括了三个主要设计:
(1)动态分辨率训练:
△4K分辨率图像处理策略
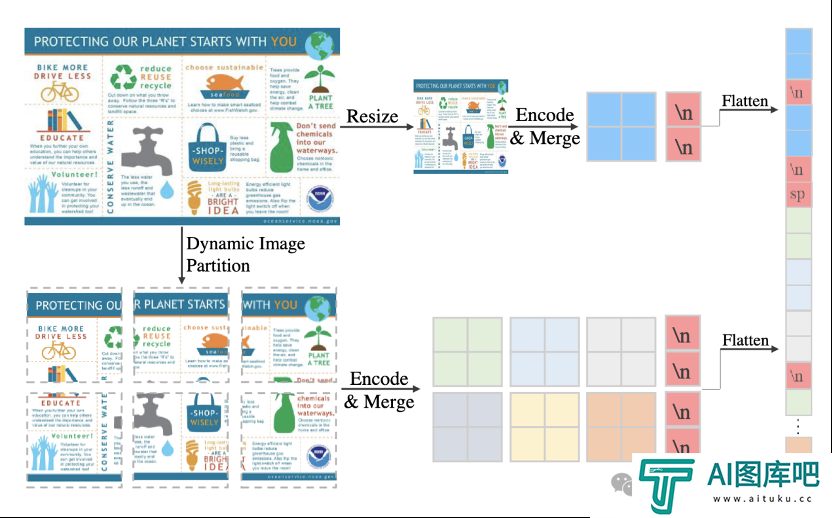
在IXC2-4KHD的框架中,输入图像在保持长宽比的情况下,被随机放大到介于输入面积和最大面积(不超过55x336x336.等价于3840 x1617分辨率)的一个中间尺寸。
随后,图像被自动切块成多个336x336的区域,分别抽取视觉特征。这种动态分辨率的训练策略可以让模型适应任意分辨率的视觉输入,同时也弥补了高分辨率训练数据不足的问题。
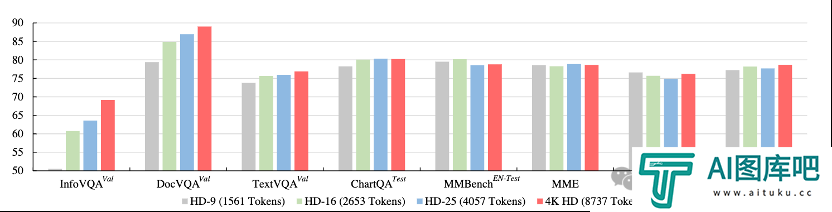
实验表明,随着动态分辨率上限的增加,模型在高分辨率图像理解任务(InfographicVQA、DocVQA、TextVQA)上实现了稳定的性能提升,并且在4K分辨率仍然未达到上界,展现了更高分辨率进一步扩展的潜力。
(2)添加切块布局信息:
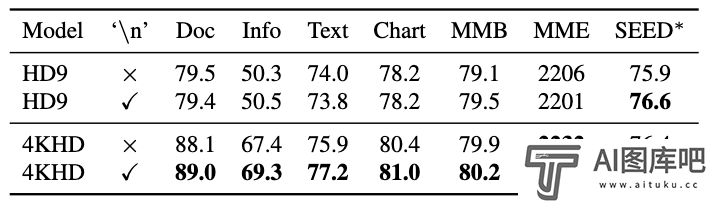
为了使模型能够适应变化丰富的动态分辨率,研究人员发现需要将切块布局信息作为额外的输入。为了实现这个目的,研究人员采取了一种简单的策略:一个特殊的‘换行’(’ ’)令牌**入到每一行的切块之后,用于告知模型切块的布局。实验表明,添加切块布局信息,对于变化幅度比较小的动态分辨率训练(HD9代表切块区域个数不超过9)影响不大,而对于动态4K分辨率训练则可以带来显著的性能提升。
(3)推理阶段扩展分辨率
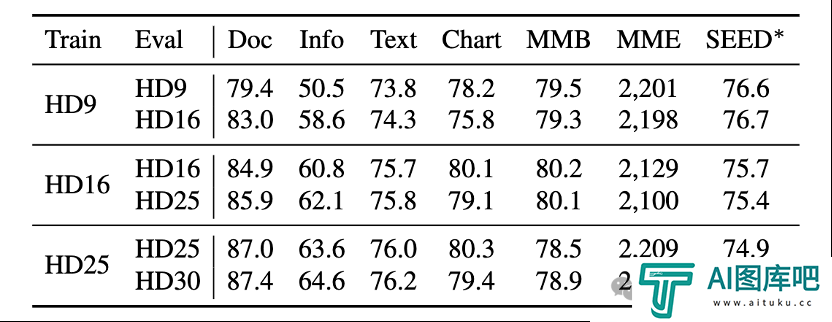
研究人员还发现,使用动态分辨率的模型,可以在推理阶段通过增加最大切块上限直接扩展分辨率,并且带来额外的性能增益。例如将HD9(最多9块)的训练模型直接使用HD16进行测试,可以在InfographicVQA上观察到高达8%的性能提升。
IXC2-4KHD将多模态大模型支持的分辨率提升到了4K的水平,研究人员表示目前这种通过增加切块个数支持更大图像输入的策略遇到了计算代价和显存的瓶颈,因此他们计划提出更加高效的策略在未来实现更高分辨率的支持。
-
![AI大模型“读懂”4K超清图像!上海AI Lab、香港中文大学联合打造多模态大模型:可自动分析网页海报内容]() AI大模型“读懂”4K超清图像!上海AI Lab、香港中文大学联合打造多模态大模型:可自动分析网页海报内容
AI大模型“读懂”4K超清图像!上海AI Lab、香港中文大学联合打造多模态大模型:可自动分析网页海报内容上海AI Lab,香港中文大学等研究机构提出的InternLM-XComposer2-4KHD多模态模型,可以自动分析PDF、网页、海报、Excel图表内容的大模型。
2025-01-31 21:54:48 -
![生成式人工智能技术杀进招聘行业:AI面试官逼疯打工人]() 生成式人工智能技术杀进招聘行业:AI面试官逼疯打工人
生成式人工智能技术杀进招聘行业:AI面试官逼疯打工人曾经出现在银行、外企、快消等领域的AI面试官,正在渗透到更多的行业。市场调查机构报告显示,预计到2024年将有43%的企业在招聘中引入AI应用。
2025-01-31 21:32:48 -
![科大讯飞4月26日发布讯飞星火V3.5春季更新丨阿里云全面支持Llama 3训练推理丨腾讯是中国AI发明专利企业最多的企业]() 科大讯飞4月26日发布讯飞星火V3.5春季更新丨阿里云全面支持Llama 3训练推理丨腾讯是中国AI发明专利企业最多的企业
科大讯飞4月26日发布讯飞星火V3.5春季更新丨阿里云全面支持Llama 3训练推理丨腾讯是中国AI发明专利企业最多的企业【AI奇点网2024年4月23日早报】本站每日播报AI业界最新资讯,触摸时代脉搏,掌握未来科技动向。事不宜迟,点击查看今日AI资讯早餐。
2025-01-31 21:07:31 -
![华为小艺输入法AI文本创作功能「小艺帮写」新增支持华为P40系列、Mate30系列手机]() 华为小艺输入法AI文本创作功能「小艺帮写」新增支持华为P40系列、Mate30系列手机
华为小艺输入法AI文本创作功能「小艺帮写」新增支持华为P40系列、Mate30系列手机据报道称,华为手机的小艺输入法近日迎来更新,「小艺帮写」功能新增支持华为 P40 系列、Mate30 系列手机。
2025-01-31 20:42:55 -
![OpenAI联合科技论坛TED发布Sora一分钟科幻短片:浓缩人类未来40年科技树,展示AI视频创作无限可能]() OpenAI联合科技论坛TED发布Sora一分钟科幻短片:浓缩人类未来40年科技树,展示AI视频创作无限可能
OpenAI联合科技论坛TED发布Sora一分钟科幻短片:浓缩人类未来40年科技树,展示AI视频创作无限可能日前,国外知名科技论坛TED联合OpenAI打造Sora一分钟长视频。在这则最新发布的视频中,描绘了未来40年的人类科技发展想象,与TED演讲活动穿插的视觉盛况。
2025-01-31 20:20:15 -
![华为Pura 70打造「AI抓拍」逆天黑科技,高清复原手抖模糊图像,拯救拍照手残党]() 华为Pura 70打造「AI抓拍」逆天黑科技,高清复原手抖模糊图像,拯救拍照手残党
华为Pura 70打造「AI抓拍」逆天黑科技,高清复原手抖模糊图像,拯救拍照手残党近日,一段网友上传的视频,让华为Pura 70的抓拍功能意外爆火。?Pura 70中搭载了名为「XD Motion」的运动算法引擎,对照片细节进行高清复原。
2025-01-31 19:50:52













-
![商汤AI视频生成器如影使用方法_如影使用教程_AI视频生成测评]() 商汤AI视频生成器如影使用方法_如影使用教程_AI视频生成测评
商汤AI视频生成器如影使用方法_如影使用教程_AI视频生成测评国内知名人工智能软件公司商汤科技近日宣布,“商汤如影SenseAvatar”数字人视频生成平台正式上线,产品愿景是“让每个人都可以轻松制作视频”,非常的直抒胸臆呀。
2024-12-17 03:24:28 -
![怎么快速给模特换装_怎么用stable diffusion给模特换装]() 怎么快速给模特换装_怎么用stable diffusion给模特换装
怎么快速给模特换装_怎么用stable diffusion给模特换装本篇教程主要运用StableDiffusion这个工具来进行操作,下面会通过几个小案例,给大家展示不同需求下,我们该如何使用StableDiffusion来辅助我们完成服装效果展示。本教程适用于电商设计场景、摄影场景等多个运用人物设计的实战中
2024-12-23 13:57:15 -
![万万没想到,兵马俑都开始跳「科目三」:阿里云通义千问APP打造“全民舞王”视频创作工具,实测效果大赞]() 万万没想到,兵马俑都开始跳「科目三」:阿里云通义千问APP打造“全民舞王”视频创作工具,实测效果大赞
万万没想到,兵马俑都开始跳「科目三」:阿里云通义千问APP打造“全民舞王”视频创作工具,实测效果大赞兵马俑跳《科目三》,是我万万没想到的。有人借助了阿里云之前走红的AI视频生成技术——「Animate Anyone」,生成出来了这个舞蹈片段。
2024-12-13 16:46:26 -
![AIGC落地实践!四招帮你快速搞定运营设计]() AIGC落地实践!四招帮你快速搞定运营设计
AIGC落地实践!四招帮你快速搞定运营设计回顾这一年,随着 AIGC 浪潮的爆发,在掌握AI工具已经成为设计师必备技能。今天这篇文章,通过三个案例流程拆解带大家从新时代设计工作流,到必备「四大招式」,到图标设计六大方向,到训练专属模型,再到全流程手把手拆解设计项目,绝对干货满满
2024-12-18 16:57:17 -
![stable diffusion初识_stable diffusion跟其他工具有什么区别]]() stable diffusion初识_stable diffusion跟其他工具有什么区别]
stable diffusion初识_stable diffusion跟其他工具有什么区别]关于Stable Diffusion的内容很多,在本篇教程里,我会先为你介绍Stable Diffusion模型的运行原理、发展历程和相较于其他AI绘图应用的区别。
2024-12-24 13:45:31 -
![如何使用 ChatGPT 调试代码]() 如何使用 ChatGPT 调试代码
如何使用 ChatGPT 调试代码当您的代码出现问题时,您可以向 ChatGPT 提供故障代码和问题描述。AI 工具将尝试识别并纠正问题。
2024-12-31 12:01:41 -
![stable SR脚本安装_stable diffusion脚本网站]() stable SR脚本安装_stable diffusion脚本网站
stable SR脚本安装_stable diffusion脚本网站上节课我们讲的4xUltraSharp是不是觉得已经很强了! 那么如果我拿出Stable SR脚本你应该如何应对呢?
2024-12-31 13:49:18 -
![怎么设置关键词权重_怎么设置Multi Prompts]() 怎么设置关键词权重_怎么设置Multi Prompts
怎么设置关键词权重_怎么设置Multi PromptsAI 绘画,顾名思义就是利用人工智能进行绘画,是人工智能生成内容(AIGC)的一个应用场景。其主要原理简单来说就是收集大量已有作品数据,通过算法对它们进行解析,最后再生成新作品,Midjourney是一个由同名研究实验室开发的人工智能程序。
2025-01-03 10:00:57 -
![零基础2天速成!白嫖「秋叶」官方AI绘画课程,卷死同事]() 零基础2天速成!白嫖「秋叶」官方AI绘画课程,卷死同事
零基础2天速成!白嫖「秋叶」官方AI绘画课程,卷死同事和「秋叶」一起学AI绘画,掌握Stable Diffusion、Midjourney的使用方法,开展AI绘画副业,搞钱!?
2024-12-17 12:53:01 -
openpose如何自定义角色_个性化角色姿势怎么定制_Controlnet深度解析
在设计角色姿势时,如何使用openpose进行姿势自定义,以及如何通过拍摄照片或使用第三方后期软件?同时,虚幻引擎对于角色姿势的编辑也很重要,本视频就并展示了如何使用优异商城中的免费资源来创建人物角色。
2024-12-19 11:43:51



![stable diffusion初识_stable diffusion跟其他工具有什么区别]](http://www.aituku.cc/uploadfile/2024/1224/d3a1bbf8bad6e281f82a2168727dfba1.png)