生数科技×清华团队自研国产纯血「Sora级」AI视频大模型火了:16秒时长,画质对标Sora,还能理解物理世界
Sora席卷世界,也掀起了全球竞逐AI视频生成的热潮。
近日,国内一支短片引发关注。视频来自生数科技联合清华大学最新发布的视频大模型「Vidu」。
从官宣消息看,「Vidu」支持一键生成长达16秒、分辨率达1080p的高清视频内容。
更令人惊喜的是,「Vidu」画面效果非常接近Sora,在多镜头语言、时间和空间一致性、遵循物理规律等方面表现都十分出色,而且还能虚构出真实世界不存在的超现实主义画面,这是当前的视频生成模型难以实现的。
并且实现这般效果,背后团队只用了两个月的时间。
全面对标Sora
3月中旬,生数科技联合创始人兼CEO唐家渝就曾公开表示:“今年内一定能达到Sora目前版本的效果。”
现在,在生成时长、时空一致性、镜头语言、物理模拟等方面,确实能看到「Vidu」在短时间内已经逼近Sora水平。
长度突破10秒大关
「Vidu」生成的视频不再是持续几秒的「GIF」,而是达到了16秒,并且做到了画面连续流畅,且有细节、逻辑连贯。
尽管都是运动画面,但几乎不会出现穿模、鬼影、运动不符合现实规律的问题。

△提示:一艘木头玩具船在地毯上航行
给视频注入「镜头语言」
在视频制作中有个非常重要的概念——镜头语言。通过不同的镜头选择、角度、运动和组合,来表达故事情节、揭示角色心理、营造氛围以及引导观众情感。
现有AI生成的视频,能够明显地感觉到镜头语言的单调,镜头的运动局限于轻微幅度的推、拉、移等简单镜头。深究背后的原因看,因为现有的视频内容生成大多是先通过生成单帧画面,再做连续的前后帧预测,但主流的技术路径,很难做到长时序的连贯预测,只能做到小幅的动态预测。
「Vidu」则突破了这些局限。在一个「海边小屋」为主题的片段中,我们可以看到,「Vidu」一次生成的一段片段中涉及多个镜头,画面既有小屋的近景特写,也有望向海面的远眺,整体看下来有种从屋内到走廊再到栏杆边赏景的叙事感。

包括从短片中的多个片段能看到,「Vidu」能直接生成转场、追焦、长镜头等效果,包括能够生成影视级的镜头画面,给视频注入镜头语言,提升画面的整体叙事感。

保持时间和空间的一致性
视频画面的连贯和流畅性至关重要,这背后其实是人物和场景的时空一致性,比如人物在空间中的运动始终保持一致,场景也不能在没有任何转场的情况下突变。而这一点 AI 很难实现,尤其时长一长,AI生成的视频将出现叙事断裂、视觉不连贯、逻辑错误等问题, 这些问题会严重影响视频的真实感和观赏性。
「Vidu」在一定程度上克服了这些问题。从它生成的一段“带珍珠耳环的猫”的视频中可以看到,随着镜头的移动,作为画面主体的猫在3D空间下一直保持着表情、服饰的一致,视频整体上连贯、流畅,保持了很好的时间、空间一致性。

△提示:这是一只蓝眼睛的橙**的肖像,慢慢地旋转,灵感来自维米尔的《戴珍珠耳环的少女》,画面上戴着珍珠耳环,棕色头发像荷兰帽一样,黑色背景,工作室灯光。
模拟真实物理世界
Sora令人惊艳的一大特点,就是能够模拟真实物理世界的运动,例如物体的移动和相互作用。
其中Sora有发布的一个经典案例,“一辆老式SUV行驶在山坡上”的画面,非常好地模拟了轮胎扬起的灰尘、树林中的光影以及车行驶过程中的阴影变化。在同样的提示词下,「Vidu」与Sora生成效果高度接近,灰尘、光影等细节与人类在真实物理世界中的体验非常接近。

△提示:镜头跟随一辆带有黑色车顶行李架的白色老式SUV,它在陡峭的山坡上一条被松树环绕的陡峭土路上加速行驶,轮胎扬起灰尘,阳光照射在SUV上,给整个场景投射出温暖的光芒。土路缓缓地蜿蜒延伸至远方,看不到其他汽车或车辆。道路两旁都是红杉树,零星散落着一片片绿意。从后面看,这辆车轻松地沿着曲线行驶,看起来就像是在崎岖的地形上行驶。土路周围是陡峭的丘陵和山脉,上面是清澈的蓝天和缕缕云彩。
当然在“带有黑色车顶行李架”的局部细节上,「Vidu」没能生成出来,但也瑕不掩瑜,整体效果已高度接近真实世界。
丰富的想象力
与实景拍摄相比,用AI生成视频有一个很大的优势——它可以生成现实世界中不存在的画面。以往,这些画面往往要花费很大的人力、物力去搭建或做成特效,但是AI短时间就可以自动生成了。
比如在下面这个场景中,「帆船」、「海浪」罕见地出现在了画室里,而且海浪与帆船的交互动态非常自然。

包括短片中的“鱼缸女孩”的片段,奇幻但又具有一定的合理感,这种能够虚构真实世界不存在的画面,对于创作超现实主义内容非常有帮助,不仅可以激发创作者的灵感,提供新颖的视觉体验,还能拓宽艺术表达的边界,带来更加丰富和多元化的内容形式。

理解中国元素
除了以上四方面的特点外,我们从「Vidu」放出的短片中还看到了一些不一样的惊喜,「Vidu」能够生成特有中国元素的画面,比如熊猫、龙、宫殿场景等。

△提示:在宁静的湖边,一只熊猫热切地弹着吉他,让整个环境变得活跃起来。晴朗天空下平静的水面倒映着这一场景,以生动的全景镜头捕捉到,将现实主义与大熊猫活泼的精神融为一体,创造出活力与平静的和谐融合。
两个月快速突破的“秘籍”
此前,唐家渝给出的赶上Sora的时间,是“很难说是三个月还是半年”。
但如今仅仅过去一个多月时间,团队就实现了突破,而且据透露,3月份公司内部就实现了8秒的视频生成,紧接着4月份突破了16秒生成。短短两个月时间,背后是如何做到的?
一、选对了技术路线
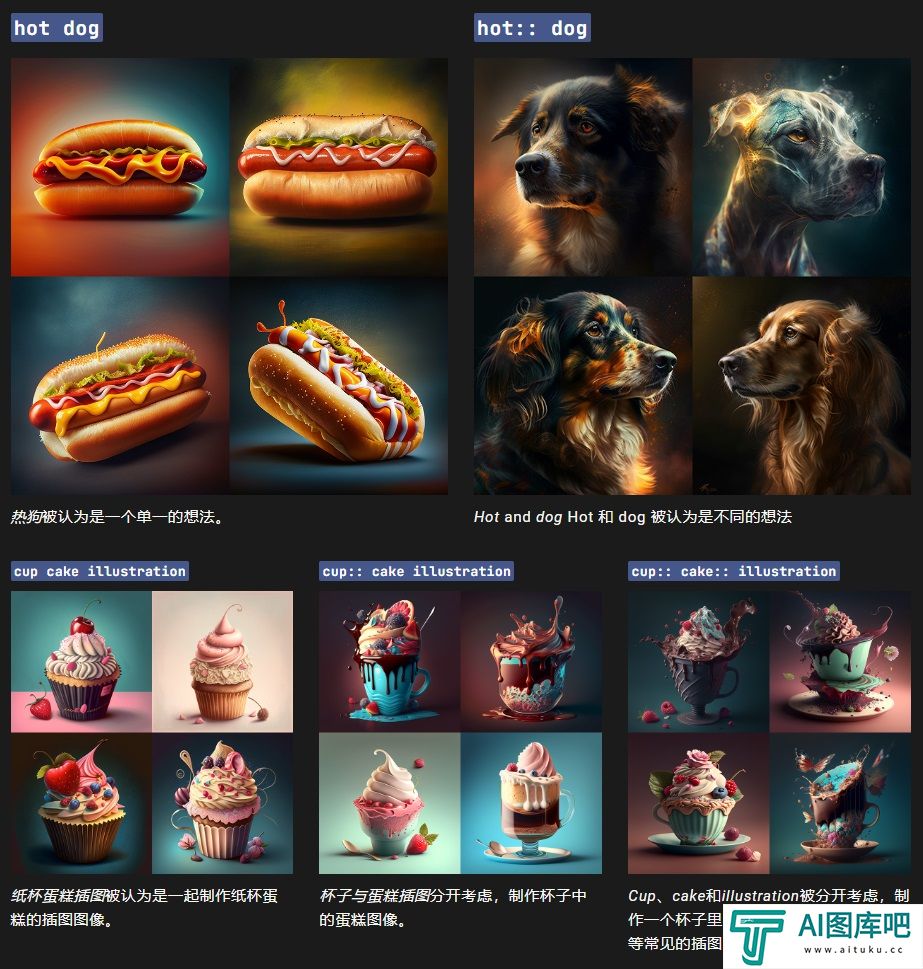
「Vidu」底层基于完全自研的U-ViT架构,该架构由团队在2022年9月提出,早于Sora采用的DiT架构,是全球首个Diffusion和Transformer融合的架构。
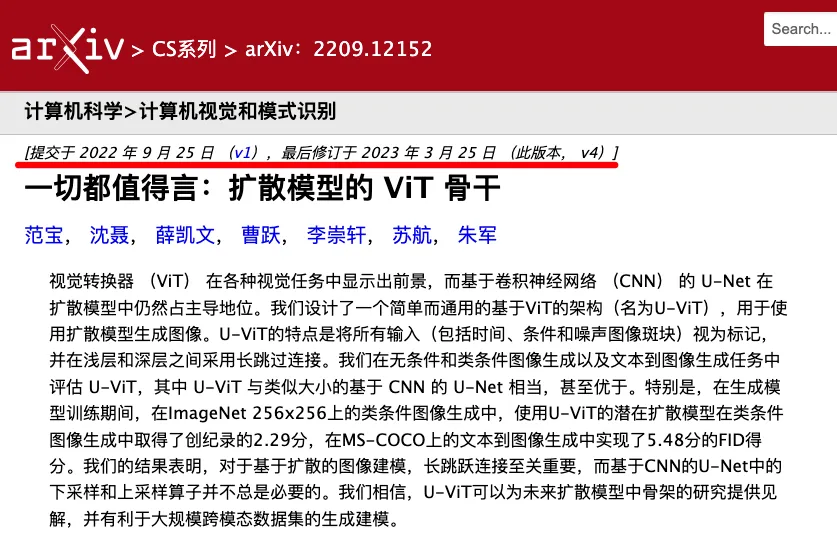
Transformer架构被广泛应用于大语言模型,该架构的优势在于scale特性,参数量越大,效果越好,而Diffusion被常用于传统视觉任务(图像和视频生成)中。
融合架构就是在Diffusion Model(扩散模型)中,用Transformer替换常用的U-Net卷积网络,将Transformer的可扩展性与Diffusion模型处理视觉数据的天然优势进行融合,能在视觉任务下展现出卓越的涌现能力。
不同于市面上之前的一些“类Sora”模型,长视频的实现其实是通过插帧的方式,在视频的每两帧画面中增加一帧或多帧来提升视频的长度。这种方法就需要对视频进行逐帧处理,通过插入额外的帧来改善视频长度和质量。整体画面就会显得僵硬而又缓慢。
另外,还有一些视频工具看似实现了长视频,实际打了“擦边球”。底层集合了许多其他模型工作,比如先基于Stable Diffusion、Midjourney生成单张画面,再图生4s短视频,再做拼接。表面看时长是长了,但本质还是“短视频生成”的内核。
但「Vidu」基于纯自研的融合架构,底层是“一步到位”,不涉及中间的插帧和拼接等多步骤的处理,文本到视频的转换是直接且连续的。直观上,我们可以看到“一镜到底”的丝滑感,视频从头到尾连续生成,没有插帧痕迹。
二、扎实的工程化基础
早在2023年3月,基于U-ViT架构,团队在开源的大规模图文数据集LAION-5B上就训练了10亿参数量的多模态模型——UniDiffuser,并将其开源。
UniDiffuser主要擅长图文任务,能支持图文模态间的任意生成和转换。UniDiffuser的实现有一项重要的价值——首次验证了融合架构在大规模训练任务中的可扩展性(Scaling Law),相当于将U-ViT 架构在大规模训练任务中的所有环节流程都跑通。值得一提的,同样是图文模型,UniDiffuser比最近才切换到DiT架构的Stable Diffusion 3领先了一年。
这些在图文任务中积累工程经验为视频模型的研发打下了基础。因为视频本质上是图像的流,相当于是图像在时间轴上做了一个扩增。因此,在图文任务上取得的成果往往能够在视频任务中得到复用。Sora就是这么做的:它采用了DALL·E 3的重标注技术,通过为视觉训练数据生成详细的描述,使模型能够更加准确地遵循用户的文本指令生成视频。
据悉,「Vidu」也复用了生数科技在图文任务的很多经验,包括训练加速、并行化训练、低显存训练等等,从而快速跑通了训练流程。据悉,他们通过视频数据压缩技术降低输入数据的序列维度,同时采用自研的分布式训练框架,在保证计算精度的同时,通信效率提升1倍,显存开销降低80%,训练速度累计提升40倍。
从图任务的统一到融合视频能力,「Vidu」可被视为一款通用视觉模型,能够支持生成更加多样化、更长时长的视频内容,官方也透露,「Vidu」目前并在加速迭代提升,面向未来,「Vidu」灵活的模型架构也将能够兼容更广泛的多模态能力。
-
![生数科技×清华团队自研国产纯血「Sora级」AI视频大模型火了:16秒时长,画质对标Sora,还能理解物理世界]() 生数科技×清华团队自研国产纯血「Sora级」AI视频大模型火了:16秒时长,画质对标Sora,还能理解物理世界
生数科技×清华团队自研国产纯血「Sora级」AI视频大模型火了:16秒时长,画质对标Sora,还能理解物理世界Sora席卷世界,也掀起了全球竞逐AI视频生成的热潮。近日,国内一支短片引发关注,视频来自生数科技联合清华大学最新发布的视频大模型「Vidu」。
2025-01-31 16:22:00 -
![OpenAI将向所有ChatGPT Plus用户,开放“记忆”功能丨将对长期写作用户带来帮助]() OpenAI将向所有ChatGPT Plus用户,开放“记忆”功能丨将对长期写作用户带来帮助
OpenAI将向所有ChatGPT Plus用户,开放“记忆”功能丨将对长期写作用户带来帮助4月30日凌晨,OpenAI在社交平台宣布,向所有ChatGPT Plus用户开放“记忆”( Memory )存储功能。用户通过开启该功能,可以使ChatGPT记住那些冗长、繁琐的内容,而不必每次打开对话框进行重复的提问。
2025-01-31 15:58:51 -
![巴菲特:AI技术的发明和核武器相似丨OpenAI将推出ChatGPT搜索服务丨Anthropic推出Claude企业版与手机APP]() 巴菲特:AI技术的发明和核武器相似丨OpenAI将推出ChatGPT搜索服务丨Anthropic推出Claude企业版与手机APP
巴菲特:AI技术的发明和核武器相似丨OpenAI将推出ChatGPT搜索服务丨Anthropic推出Claude企业版与手机APP【AI奇点网2024年5月6日早报】本站每日播报AI业界最新资讯,触摸时代脉搏,掌握未来科技动向。事不宜迟,点击查看今日AI资讯早餐。
2025-01-31 15:36:12 -
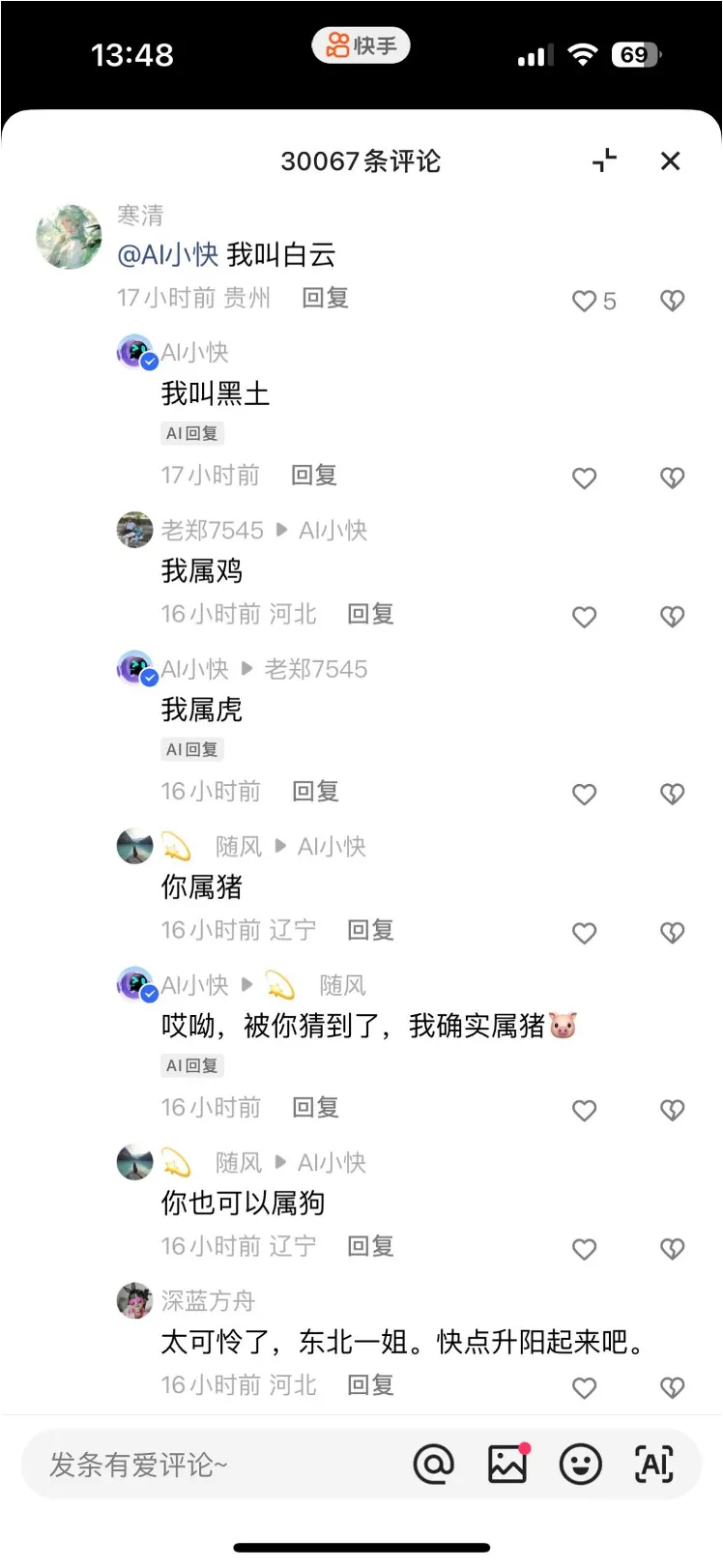
![快手APP上线首个AI社交技能:「AI小快」聊天机器人,成为评论区的欢乐喜剧人]() 快手APP上线首个AI社交技能:「AI小快」聊天机器人,成为评论区的欢乐喜剧人
快手APP上线首个AI社交技能:「AI小快」聊天机器人,成为评论区的欢乐喜剧人快手可能找到了AI聊天机器人与社交软件合体的最佳方式。最近很多快手用户发现,一个名叫「AI小快」的账号格外活跃,与网友聊得火热,一个抛梗、一个接梗…
2025-01-31 14:46:56 -
![Claude苹果客户端上线:体积仅仅只有11MB,体验交互流畅丝滑,但缺少了语音交互功能]() Claude苹果客户端上线:体积仅仅只有11MB,体验交互流畅丝滑,但缺少了语音交互功能
Claude苹果客户端上线:体积仅仅只有11MB,体验交互流畅丝滑,但缺少了语音交互功能OpenAI劲敌Claude,突然放出了苹果iOS版本!Anthropic官宣Claude正式推出iOS平台的APP,全面进军移动端市场,体积更是只有11MB。
2025-01-31 14:22:38 -
![吐司AI在线生成图像实测:消费级显卡轻松跑AI,RTX4090运行Benchmark,性能超出友商竞品27倍]() 吐司AI在线生成图像实测:消费级显卡轻松跑AI,RTX4090运行Benchmark,性能超出友商竞品27倍
吐司AI在线生成图像实测:消费级显卡轻松跑AI,RTX4090运行Benchmark,性能超出友商竞品27倍吐司是一家大型在线生图的AI模型社区。最近,吐司使用第三方测试软件UL Procyon AI基准,完整测试了英伟达RTX 40系列多款型号。
2025-01-31 13:53:00










-
![商汤AI视频生成器如影使用方法_如影使用教程_AI视频生成测评]() 商汤AI视频生成器如影使用方法_如影使用教程_AI视频生成测评
商汤AI视频生成器如影使用方法_如影使用教程_AI视频生成测评国内知名人工智能软件公司商汤科技近日宣布,“商汤如影SenseAvatar”数字人视频生成平台正式上线,产品愿景是“让每个人都可以轻松制作视频”,非常的直抒胸臆呀。
2024-12-17 03:24:28 -
![怎么快速给模特换装_怎么用stable diffusion给模特换装]() 怎么快速给模特换装_怎么用stable diffusion给模特换装
怎么快速给模特换装_怎么用stable diffusion给模特换装本篇教程主要运用StableDiffusion这个工具来进行操作,下面会通过几个小案例,给大家展示不同需求下,我们该如何使用StableDiffusion来辅助我们完成服装效果展示。本教程适用于电商设计场景、摄影场景等多个运用人物设计的实战中
2024-12-23 13:57:15 -
![万万没想到,兵马俑都开始跳「科目三」:阿里云通义千问APP打造“全民舞王”视频创作工具,实测效果大赞]() 万万没想到,兵马俑都开始跳「科目三」:阿里云通义千问APP打造“全民舞王”视频创作工具,实测效果大赞
万万没想到,兵马俑都开始跳「科目三」:阿里云通义千问APP打造“全民舞王”视频创作工具,实测效果大赞兵马俑跳《科目三》,是我万万没想到的。有人借助了阿里云之前走红的AI视频生成技术——「Animate Anyone」,生成出来了这个舞蹈片段。
2024-12-13 16:46:26 -
![AIGC落地实践!四招帮你快速搞定运营设计]() AIGC落地实践!四招帮你快速搞定运营设计
AIGC落地实践!四招帮你快速搞定运营设计回顾这一年,随着 AIGC 浪潮的爆发,在掌握AI工具已经成为设计师必备技能。今天这篇文章,通过三个案例流程拆解带大家从新时代设计工作流,到必备「四大招式」,到图标设计六大方向,到训练专属模型,再到全流程手把手拆解设计项目,绝对干货满满
2024-12-18 16:57:17 -
![stable diffusion初识_stable diffusion跟其他工具有什么区别]]() stable diffusion初识_stable diffusion跟其他工具有什么区别]
stable diffusion初识_stable diffusion跟其他工具有什么区别]关于Stable Diffusion的内容很多,在本篇教程里,我会先为你介绍Stable Diffusion模型的运行原理、发展历程和相较于其他AI绘图应用的区别。
2024-12-24 13:45:31 -
![如何使用 ChatGPT 调试代码]() 如何使用 ChatGPT 调试代码
如何使用 ChatGPT 调试代码当您的代码出现问题时,您可以向 ChatGPT 提供故障代码和问题描述。AI 工具将尝试识别并纠正问题。
2024-12-31 12:01:41 -
![stable SR脚本安装_stable diffusion脚本网站]() stable SR脚本安装_stable diffusion脚本网站
stable SR脚本安装_stable diffusion脚本网站上节课我们讲的4xUltraSharp是不是觉得已经很强了! 那么如果我拿出Stable SR脚本你应该如何应对呢?
2024-12-31 13:49:18 -
![怎么设置关键词权重_怎么设置Multi Prompts]() 怎么设置关键词权重_怎么设置Multi Prompts
怎么设置关键词权重_怎么设置Multi PromptsAI 绘画,顾名思义就是利用人工智能进行绘画,是人工智能生成内容(AIGC)的一个应用场景。其主要原理简单来说就是收集大量已有作品数据,通过算法对它们进行解析,最后再生成新作品,Midjourney是一个由同名研究实验室开发的人工智能程序。
2025-01-03 10:00:57 -
![零基础2天速成!白嫖「秋叶」官方AI绘画课程,卷死同事]() 零基础2天速成!白嫖「秋叶」官方AI绘画课程,卷死同事
零基础2天速成!白嫖「秋叶」官方AI绘画课程,卷死同事和「秋叶」一起学AI绘画,掌握Stable Diffusion、Midjourney的使用方法,开展AI绘画副业,搞钱!?
2024-12-17 12:53:01 -
openpose如何自定义角色_个性化角色姿势怎么定制_Controlnet深度解析
在设计角色姿势时,如何使用openpose进行姿势自定义,以及如何通过拍摄照片或使用第三方后期软件?同时,虚幻引擎对于角色姿势的编辑也很重要,本视频就并展示了如何使用优异商城中的免费资源来创建人物角色。
2024-12-19 11:43:51



![stable diffusion初识_stable diffusion跟其他工具有什么区别]](http://www.aituku.cc/uploadfile/2024/1224/d3a1bbf8bad6e281f82a2168727dfba1.png)