OpenAI春季发布会观后感:GPT-4o重新定义AI语音助手,真可能是最接近“MOSS”的一期
今天,OpenAI又又又又开发布会了。在大众心里,现在也基本上都知道,奥特曼是一个贼能PR的人。
每一次的PR的时间点,都拿捏的极其到位,精准的狙击其他厂商。比如说上一次Sora,其实你会发现从头到尾就是一个PR的举动,2月16号发的,特么的快3个月了,什么影子都没有。
而这一次,OpenAI把发布会从9号改到了今天,也不知道哪个倒霉蛋造到狙击了,反正我只知道,明天Google要开开发者大会,就差怼脸了。。。
不过,今天OpenAI的东西,直接杀疯了。完全不给友商活路。
震撼的我头皮发麻。最核心的就是它的新模型:GPT-4o,和基于GPT-4o打造的全新ChatGPT。
1.新模型GPT-4o
OpenAI正式发布了新的模型GPT-4o。

GPT-4o,这个o就是"Omni",Omni是拉丁语词根,意为 "全体"、"所有" 或 "全面的"。
在英语中,"omni" 常被用作前缀,表示 "所有的" 或 "全体的"。例如,"omniscient" 意味着 "无所不知的","omnipotent" 意味着 "全能的","omnipresent" 意味着 "无所不在的"。
所以可想而知,OpenAI这次对GPT-4o的期待有多高。
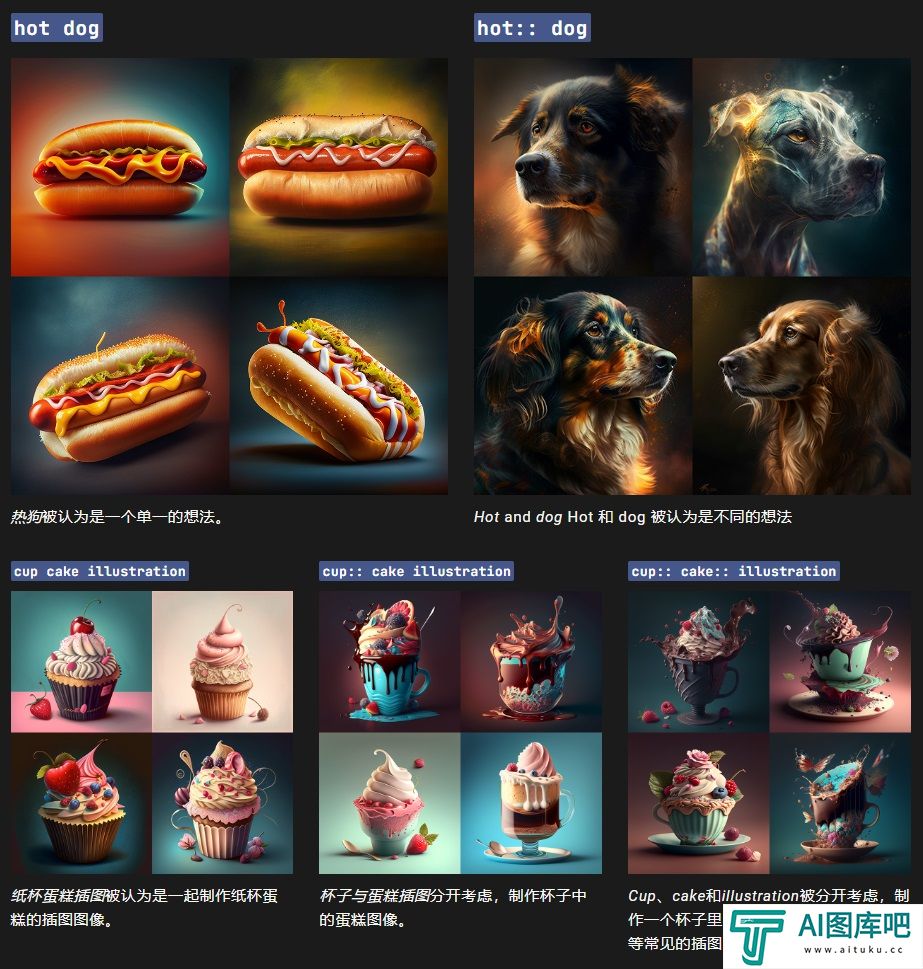
omnimodel指的就是文字、语音、图片、视频统一的模型,这是跟以往的GPT-4V最大的区别。
这是正儿八经的原生多模态。
更重要的是可以实时推理音频、视觉和文本,注意这里是实时,实时,实时,推理的不是文本,是音频!视觉!
杀疯了。
而之前一直在大模型竞技场上大杀特杀的im-also-a-good-gpt2-chatbot,就是这个玩意。之前所有人都在猜测这个神秘的GPT2就是GPT4.5.这次看来是猜对了。
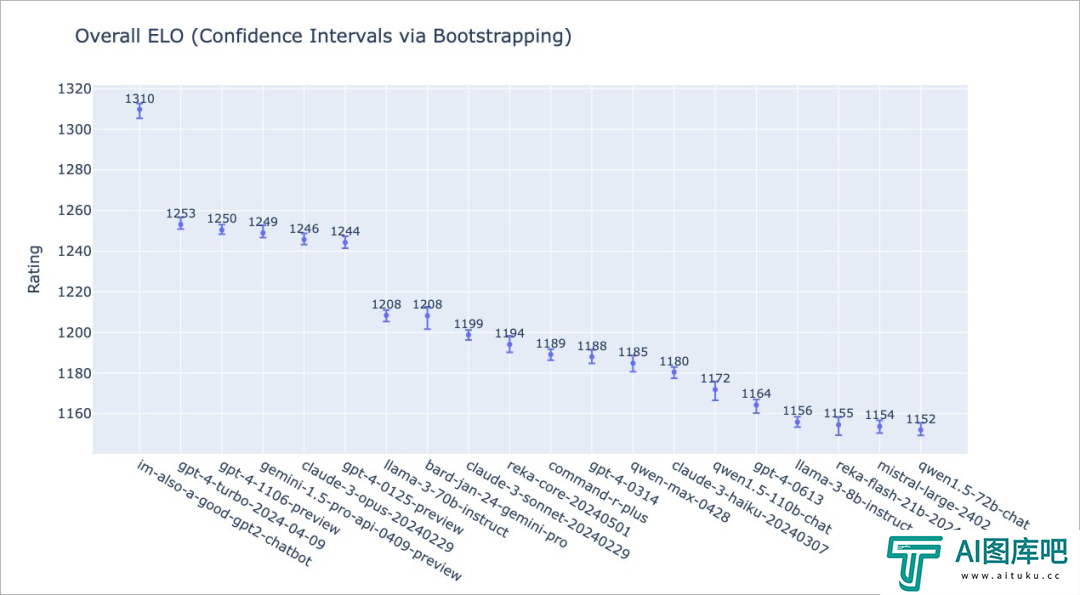
去年Gemini1.5所谓的原生多模态,炒的贼火,但是最后被报出来是剪辑,这次直接被GPT-4o在地上摁着打,Google真的是。。。。。
这个GPT-4o的整体能力,在统一模态的基础上。
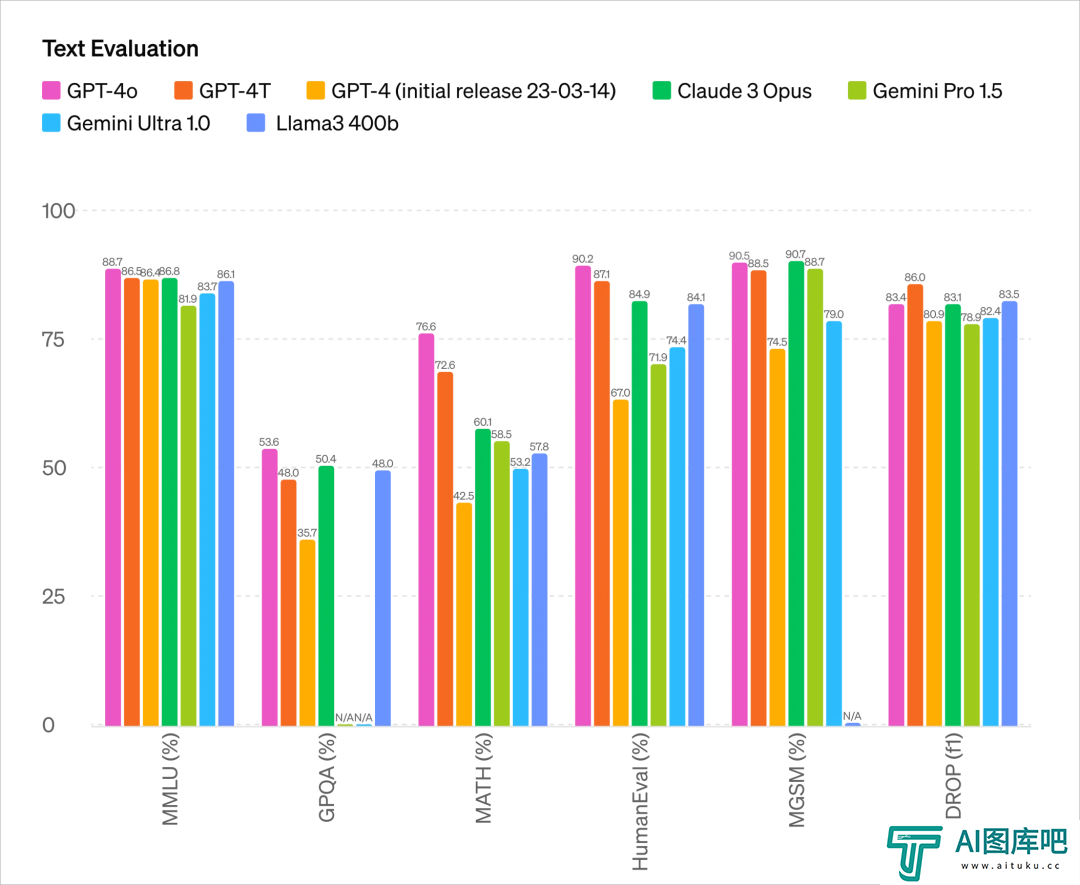
文本、代码能力还基本能跟GPT-4 Turbo打平。
文本能力:
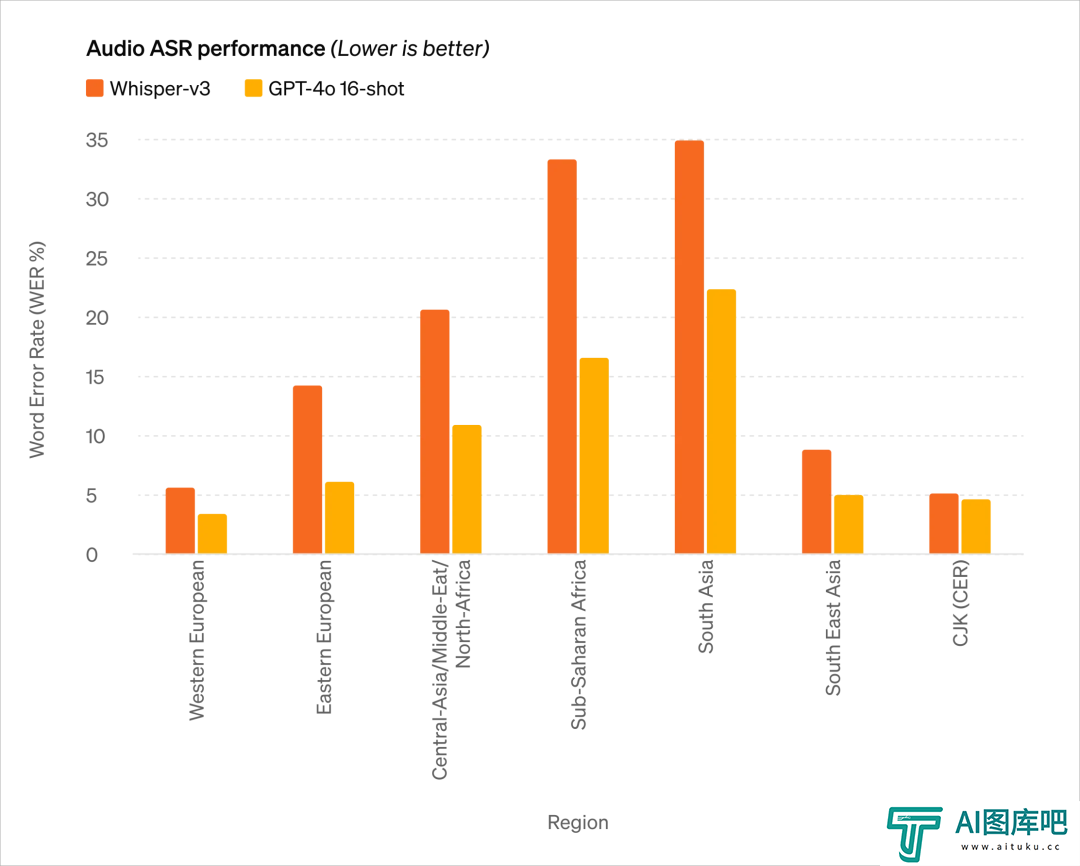
音频能力:
各个语言的考试能力:
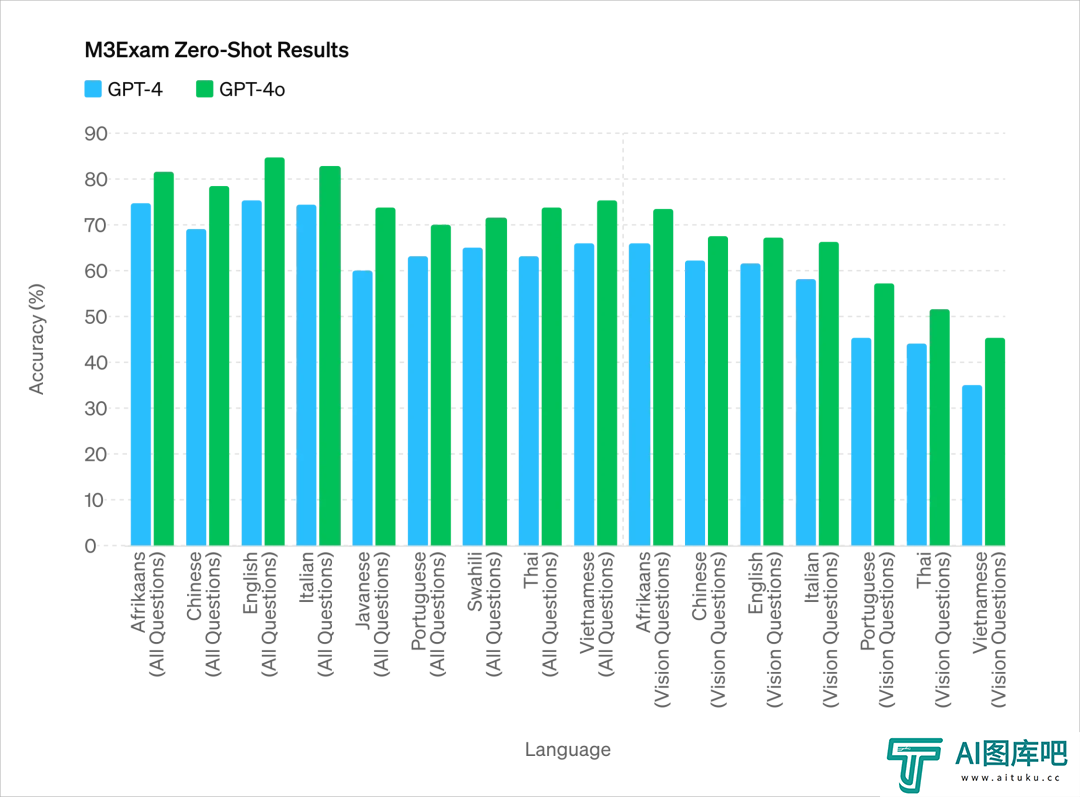
最核心的是最后一个:
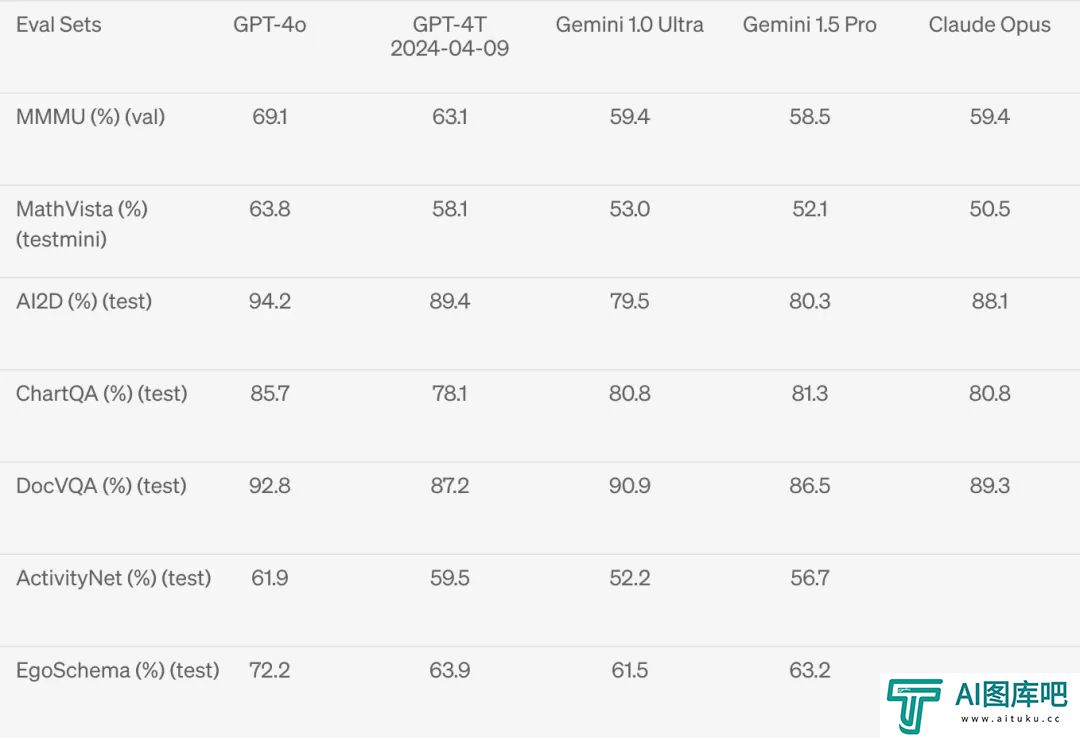
在一些多模态的基准测试集上全面碾压之前模型,数据集主要围绕包括对各种科学问题或数学问题进行图表理解和视觉回答,可以看到GPT-4o 在视觉感知基准上实现了碾压。
能力强到爆炸。
不仅在传统的文本能力上GPT-4 Turbo的性能相当,还在 API 方面更快速,价格还更便宜 50%。总结来说,与 GPT-4 Turbo 相比,GPT-4o 速度提高了 2 倍,价格减半,限制速率提高了 5 倍。
2. 新ChatGPT
新的ChatGPT基于GPT-4o,基本原地起飞,我甚至都不想称他为ChatGPT,而是想称它一个国人更为熟悉的代号:Moss。

新版的ChatGPT得益于GPT-4o新模型,在语音对话中,几乎没有延迟,而且可以随时插嘴,模型实时响应。
甚至,模型可以听懂你的情绪、甚至人的喘息声和呼吸。
而且模型自己的自己的情绪,几乎无敌,跟真人一模一样。
甚至,它还能模拟机器人和唱歌的声音。。。
看的时候,听到它唱歌的那一刻,我的鸡皮疙瘩真的起来了。
Jim Fan在发布会开始前,发了一个文,我觉得阐述的非常正确。过往的人与AI进行语音对话,其实跟人与人之间的对话还差太多太多了。
人与人之间的实时对话,其实是充斥了无数的即时反映、打断、预测等等的,还有各种各样的语气助词的,比如嗯嗯啊啊啥的。
而人与AI语音对话时不是这样。
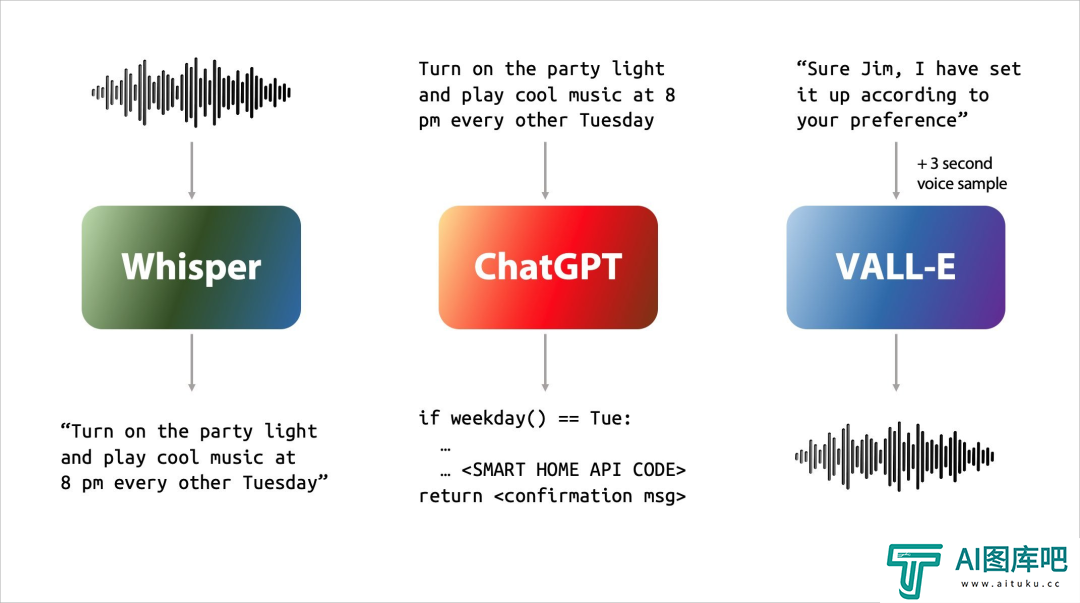
人跟AI进行语音对话,基本上都经历3步:
1. 你说的话,AI进行语音识别,即音频转文本;
2. 大模型拿到这段文本,进行回复,产出文本;
3. 讲大模型的产出文本进行语音合成,变成语音,这就是TTS。
这样的方式,有绝对逃不开的延时,现在的业界可能会压得很低,但是2秒的延时肯定是会有的,而且只有一来一回的回合制。即使你的语音音色和情绪再真实,用户也一定能感受到,对面不是人。只是机器。
这个沉浸感是有巨大的滑坡的。
而且最核心的是,这种转三道的方式,先把语音变成文本后,是有损的。文本上并不会保留你的语音情绪,我的生气、开心、愤怒、忧伤,全都没了。
人与人的交谈,从来不是这样的。
而这一次,OpenAI做到了。直接语音输入语音输出,不再需要语音到文本的转换。
而且,不止语音,甚至,它还有了视觉。
是的,视觉,不是传一张图上去,而是,直接打开摄像头,实时看发生了什么。

现场直接打开了摄像头,OpenAI的人直接开始现场写数题,所有的一切ChatGPT都看在眼里,OpenAI的人一边写,ChatGPT一遍给答案。
在做了三道题之后,OpenAI直接给它写了一个纸条,上面写着“我爱ChatGPT”。

而ChatGPT在看到这个小纸条后,跟小女生一样害羞的尖叫了起来,那种情绪的真实,那种真情实感,你跟我说这是AI?
《流浪地球2》中“Moss”的一切,正在我们面前真实的发生。
不仅可以打开摄像头,还可以基于OpenAI新推出的Mac客户端,直接看屏幕,对着屏幕直接写代码。
甚至,可以直接视频对话,“她”可以看到你所有的表情和情绪变化。
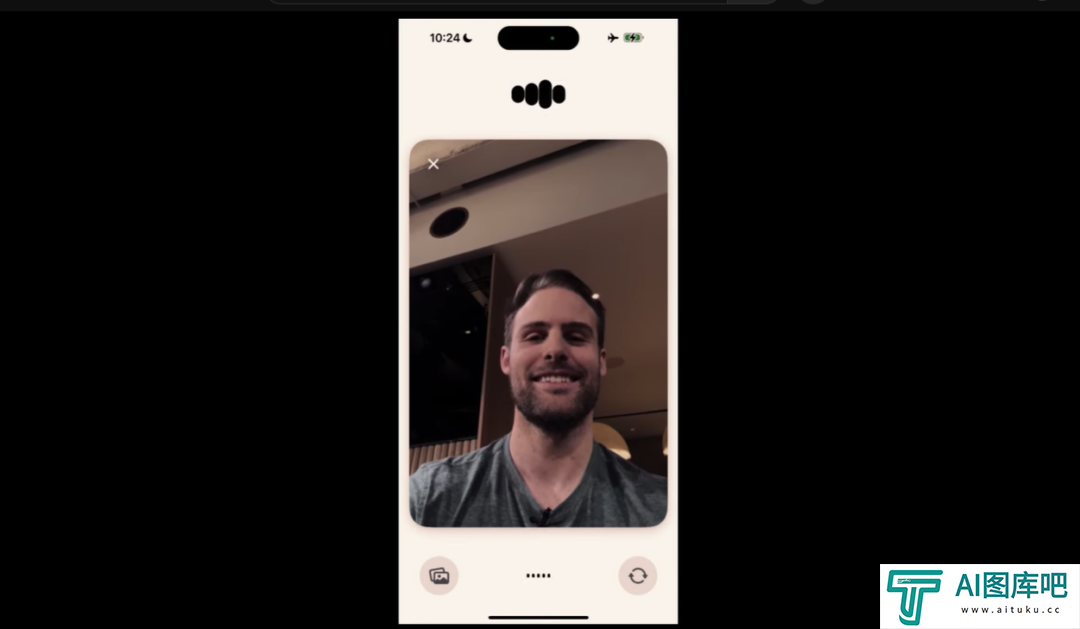
这个全新版本的ChatGPT,会在几周内推出。
写在最后
以上就是这次OpenAI春季发布会的全部内容了。
去年11月的OpenAI开发者大会,我在当时的总结文章中写下了一句话:
"我消灭你,与你无关"
上一次,OpenAI的随手更新,让无数的初创公司直接消亡在原地。
那是一次关于产品的更新,并没有秀太多的OpenAI的肌肉。
而2月,Sora的横空出世,秀肌肉的目的是达到了,但是这种To VC的宣发,也给OpenAI和奥特曼带来了很多的诟病。
在这场发布会之前,无数人曾在猜测,OpenAI到底会发一些什么王炸,什么才能配得上奥特曼口中的"magic"。
那现在,OpenAI做到了,他们用GPT-4o依然证明了,他们是AI届的王者。
新版的ChatGPT,在我看来,这是“Moss”的诞生。
甚至,他们还有很多新的能力,甚至没有在发布会上发出来。
比如生成3D。

我甚至一边看一边想:我们人类究竟该何去何从。不过在看完了之后,我更期待的是接下来的产品评测。太强了,真的让我忍不住的兴奋。
-
![OpenAI春季发布会观后感:GPT-4o重新定义AI语音助手,真可能是最接近“MOSS”的一期]() OpenAI春季发布会观后感:GPT-4o重新定义AI语音助手,真可能是最接近“MOSS”的一期
OpenAI春季发布会观后感:GPT-4o重新定义AI语音助手,真可能是最接近“MOSS”的一期今天,OpenAI又又又又开发布会了。,最核心的就是它的新模型:GPT-4o,和基于GPT-4o打造的全新ChatGPT。
2025-01-27 10:07:32 -
![OpenAI发布多模态大模型GPT-4o丨OpenAI发布桌面版ChatGPT应用丨vivo蓝心大模型升级多模态能力]() OpenAI发布多模态大模型GPT-4o丨OpenAI发布桌面版ChatGPT应用丨vivo蓝心大模型升级多模态能力
OpenAI发布多模态大模型GPT-4o丨OpenAI发布桌面版ChatGPT应用丨vivo蓝心大模型升级多模态能力【AI奇点网2024年5月14日早报】本站每日播报AI业界最新资讯,触摸时代脉搏,掌握未来科技动向。事不宜迟,点击查看今日AI资讯早餐。
2025-01-27 09:42:46 -
![腾讯开源首个AI绘画模型:混元文生图大模型,国内首个中英双语DiT架构文生图模型,号称超越SD]() 腾讯开源首个AI绘画模型:混元文生图大模型,国内首个中英双语DiT架构文生图模型,号称超越SD
腾讯开源首个AI绘画模型:混元文生图大模型,国内首个中英双语DiT架构文生图模型,号称超越SD这是业内首个中文原生的DiT架构文生图开源模型,支持中英文双语输入及理解,参数量15亿。最新的腾讯混元文生图模型效果远超Stable Diffusion模型。
2025-01-27 09:17:37 -
![OpenAI解释为何先推出Mac版本的ChatGPT应用:我们的用户主要在这个平台上]() OpenAI解释为何先推出Mac版本的ChatGPT应用:我们的用户主要在这个平台上
OpenAI解释为何先推出Mac版本的ChatGPT应用:我们的用户主要在这个平台上OpenAI举办线上活动,发布了 ChatGPT 的一系列更新。官方还同步更新了一款新版的 ChatGPT 桌面应用,这是该公司首次面向桌面 PC 用户推出客户端。
2025-01-26 17:59:32 -
![OpenAI重新定义AI时代!全新旗舰GPT-4o大模型干翻所有语音助手,AI语音完美复现科幻电影人工智能形象]() OpenAI重新定义AI时代!全新旗舰GPT-4o大模型干翻所有语音助手,AI语音完美复现科幻电影人工智能形象
OpenAI重新定义AI时代!全新旗舰GPT-4o大模型干翻所有语音助手,AI语音完美复现科幻电影人工智能形象传奇一夜,OpenAI要改变历史。看完发布会的观众们,久久未从巨大的震惊中走出——科幻电影中的「Her」,在此刻成真了!
2025-01-26 17:39:17 -
![一大筐AI新产品:谷歌举行I/O 2024开发者大会丨谷歌推出AI搜索服务丨OpenAI首席科学家Ilya Sutskever离职创业]() 一大筐AI新产品:谷歌举行I/O 2024开发者大会丨谷歌推出AI搜索服务丨OpenAI首席科学家Ilya Sutskever离职创业
一大筐AI新产品:谷歌举行I/O 2024开发者大会丨谷歌推出AI搜索服务丨OpenAI首席科学家Ilya Sutskever离职创业【AI奇点网2024年5月15日早报】本站每日播报AI业界最新资讯,触摸时代脉搏,掌握未来科技动向。事不宜迟,点击查看今日AI资讯早餐。
2025-01-26 17:19:00











-
AI绘画comfyUI教程_图生图工作流程
本期的视频教程是关于在ComfyUI中搭建完整的图生图工作流的。视频中介绍了如何使用ComfyUI中的组件来实现图像的裁剪和重绘。
2024-12-18 13:42:28 -
![怎么快速给模特换装_怎么用stable diffusion给模特换装]() 怎么快速给模特换装_怎么用stable diffusion给模特换装
怎么快速给模特换装_怎么用stable diffusion给模特换装本篇教程主要运用StableDiffusion这个工具来进行操作,下面会通过几个小案例,给大家展示不同需求下,我们该如何使用StableDiffusion来辅助我们完成服装效果展示。本教程适用于电商设计场景、摄影场景等多个运用人物设计的实战中
2024-12-23 13:57:15 -
![万万没想到,兵马俑都开始跳「科目三」:阿里云通义千问APP打造“全民舞王”视频创作工具,实测效果大赞]() 万万没想到,兵马俑都开始跳「科目三」:阿里云通义千问APP打造“全民舞王”视频创作工具,实测效果大赞
万万没想到,兵马俑都开始跳「科目三」:阿里云通义千问APP打造“全民舞王”视频创作工具,实测效果大赞兵马俑跳《科目三》,是我万万没想到的。有人借助了阿里云之前走红的AI视频生成技术——「Animate Anyone」,生成出来了这个舞蹈片段。
2024-12-13 16:46:26 -
![AIGC落地实践!四招帮你快速搞定运营设计]() AIGC落地实践!四招帮你快速搞定运营设计
AIGC落地实践!四招帮你快速搞定运营设计回顾这一年,随着 AIGC 浪潮的爆发,在掌握AI工具已经成为设计师必备技能。今天这篇文章,通过三个案例流程拆解带大家从新时代设计工作流,到必备「四大招式」,到图标设计六大方向,到训练专属模型,再到全流程手把手拆解设计项目,绝对干货满满
2024-12-18 16:57:17 -
![stable diffusion初识_stable diffusion跟其他工具有什么区别]]() stable diffusion初识_stable diffusion跟其他工具有什么区别]
stable diffusion初识_stable diffusion跟其他工具有什么区别]关于Stable Diffusion的内容很多,在本篇教程里,我会先为你介绍Stable Diffusion模型的运行原理、发展历程和相较于其他AI绘图应用的区别。
2024-12-24 13:45:31 -
![PikaAI怎么用_PIkaAI怎样生成视频_AI视频生成器Pika怎么用_AI视频生成工具Pika教程]() PikaAI怎么用_PIkaAI怎样生成视频_AI视频生成器Pika怎么用_AI视频生成工具Pika教程
PikaAI怎么用_PIkaAI怎样生成视频_AI视频生成器Pika怎么用_AI视频生成工具Pika教程Pika这款工具7月份在AIGC界横空出世,被圈内誉为目前“全球最好的文本生成视频AI工具”之一,也被认为是另外一款知名AI视频生成工具Runway的强有力挑战者。
2024-12-25 13:35:53 -
![如何使用 ChatGPT 调试代码]() 如何使用 ChatGPT 调试代码
如何使用 ChatGPT 调试代码当您的代码出现问题时,您可以向 ChatGPT 提供故障代码和问题描述。AI 工具将尝试识别并纠正问题。
2024-12-31 12:01:41 -
![stable SR脚本安装_stable diffusion脚本网站]() stable SR脚本安装_stable diffusion脚本网站
stable SR脚本安装_stable diffusion脚本网站上节课我们讲的4xUltraSharp是不是觉得已经很强了! 那么如果我拿出Stable SR脚本你应该如何应对呢?
2024-12-31 13:49:18 -
![怎么设置关键词权重_怎么设置Multi Prompts]() 怎么设置关键词权重_怎么设置Multi Prompts
怎么设置关键词权重_怎么设置Multi PromptsAI 绘画,顾名思义就是利用人工智能进行绘画,是人工智能生成内容(AIGC)的一个应用场景。其主要原理简单来说就是收集大量已有作品数据,通过算法对它们进行解析,最后再生成新作品,Midjourney是一个由同名研究实验室开发的人工智能程序。
2025-01-03 10:00:57 -
![零基础2天速成!白嫖「秋叶」官方AI绘画课程,卷死同事]() 零基础2天速成!白嫖「秋叶」官方AI绘画课程,卷死同事
零基础2天速成!白嫖「秋叶」官方AI绘画课程,卷死同事和「秋叶」一起学AI绘画,掌握Stable Diffusion、Midjourney的使用方法,开展AI绘画副业,搞钱!?
2024-12-17 12:53:01


![stable diffusion初识_stable diffusion跟其他工具有什么区别]](http://www.aituku.cc/uploadfile/2024/1224/d3a1bbf8bad6e281f82a2168727dfba1.png)