音效师狂喜!谷歌DeepMind发布首个AI视频全自动配音工具V2A:一个人轻松干完后期的活

谷歌发布新一代AI视频自动配音工具,AI视频开启「有声时代」!?
6月17日,谷歌人工智能团队DeepMind发布了一个名为V2A(Video-to-Audio)的AI架构系统,顾名思义即“视频转音频”,能根据画面内容或者手动输入的提示词直接为视频配音。
该模型最大的功能在于,可为任何视频自动创建合适的音轨BGM,在实践中取得了十分有效的进展,可以大大降低视频配音的制作成本。
当前Sora、Pika、可灵以及Runway等视频模型已经能输出逼真的短片,但它们均输出的是默片。
谷歌V2A系统的特点,便是V2A能依靠自身的多模态视觉能力理解视频当中的信息。V2A能看懂画面,知道画面里正在发生什么,应该出现什么声音。
?举个例子,比如输入一则主题为「在黑暗中行走」的无声视频,添加“电影、恐怖片、音乐、紧张、混凝土上的脚步声”等文本提示后,AI模型就能根据提示词生成恐怖片风格的背景音效,十分逼真。
脚步声基本吻合人物走动的节奏,随着画面的切换,脚步声也随之消失,毛骨悚然的紧张感拉满。
为了能够贴近Sora热点,谷歌V2A的开发团队使用了不少Sora生成的视频片段作为输入范例。
比如上边这段Sora生成的水母漂荡影像,营造出了负压十足的深海水压感。
下方这则短片也是Sora的样片,经由V2A生成的音乐配乐后的视频颇有西部大片的感觉。
当然也不是每一次生成的配音都是完美的,比如架子鼓的敲击,这种复杂的音频场景就会发生音画不同步的情况。
除了纯粹的配音外,谷歌V2A给了创作者很大的自由度。
影片创作者可以根据可以通过明确的“正面”提示词,引导模型输出所需的声音,或者输入“负面”提示词,以规避不想出现的音效。让用户可以创作不同的音画匹配。
让我们看下面这个Sora样片的配音效果,提供了两种截然不同的画面情绪氛围:
【视频①】营造星际穿越的孤独感
【视频②】营造星际穿越的史诗感
只需简单调整提示词,谷歌V2A就能迅速给创作者提供风格迥异的音频。
当然,V2A还允许用户通过输入“正面提示词”来引导模型输出所需的声音,或输入“负面提示词”来引导其避免出现不需要的声音,这给了创作者更大的控制力。
与其他普通的AI音频生成工具不同,V2A输出的视频是配音完毕的完整片段,无需人工对齐音频与视频,可实现音画自动对齐。
V2A配音案例——?狼吼
V2A配音案例——?电吉他
谷歌DeepMind也承认,该AI系统目前仍然存在较大的局限性。如果输入的视频质量不高,或者无法吻合预训练的视频类型,那么输出的音频质量也会出现明显的下降。
因此,谷歌目前正在改善安全性并补齐当前V2A在人物对口型方面的短板,才会正式向公众发布这一AI配音工具。
这套AI配音系统是如何工作的呢?
谷歌DeepMind的研究人员称,V2A系统首先会将视频进行压缩,然后借助扩散模型从中随机抽取噪声以提炼和学习音画对应的音频信息。
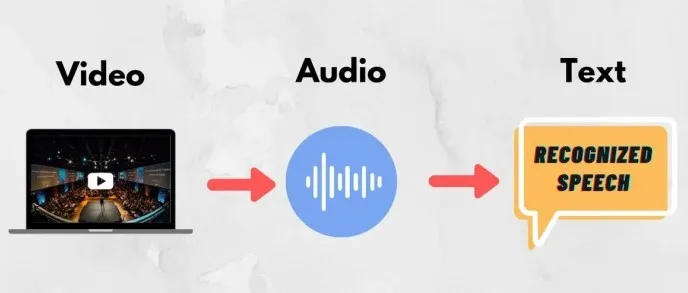
该过程经由视觉输入和自然语言提示作为引导,以匹配提示词生成对应的音频。最后,音频输出并解码,转为一般音频文件并与视频数据组合对齐。
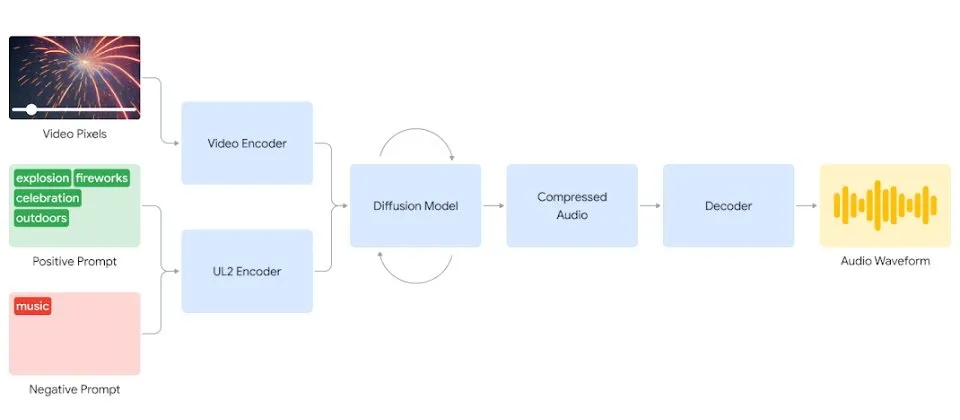
为了能引导生成更高质量的音频,谷歌DeepMind的研究人员在训练过程中添加了许多人工标注的信息。V2A系统渐渐学会了将特定的音频事件与各种视觉场景相关联,并且将提示词中提供的信息与之匹配。
需要注意到是,谷歌目前并不打算向公众开放V2A系统,还需要许多准备工作。

考虑到Fake News(假新闻)粗制滥造的可能,谷歌DeepMind强调,他们会考虑在V2A系统AI生成的内容添加元数据水印,防止外界滥用该技术。
从文生图到文生视频,到音画同步,谷歌V2A系统的发布将给影视内容创作的生态带来巨大的改变,尤其是在后期剪辑与动画制作方面。
相信今年将是AI视频爆发的元年。
项目主页:https://deepmind.google/discover/blog/generating-audio-for-video/
-
![音效师狂喜!谷歌DeepMind发布首个AI视频全自动配音工具V2A:一个人轻松干完后期的活]() 音效师狂喜!谷歌DeepMind发布首个AI视频全自动配音工具V2A:一个人轻松干完后期的活
音效师狂喜!谷歌DeepMind发布首个AI视频全自动配音工具V2A:一个人轻松干完后期的活谷歌人工智能团队DeepMind发布了一个名为V2A(Video-to-Audio)的AI架构系统,新一代AI视频自动配音工具,AI视频开启「有声时代」!?
2025-01-17 11:26:13 -
![Anthropic发布新一代Claude 3.5 Sonnet丨微信输入法V1.2版提供AI问答丨北京首例「AI换脸软件」侵权案宣判]() Anthropic发布新一代Claude 3.5 Sonnet丨微信输入法V1.2版提供AI问答丨北京首例「AI换脸软件」侵权案宣判
Anthropic发布新一代Claude 3.5 Sonnet丨微信输入法V1.2版提供AI问答丨北京首例「AI换脸软件」侵权案宣判【AI奇点网2024年6月21日早报】本站每日播报AI业界最新资讯,触摸时代脉搏,掌握未来科技动向。事不宜迟,点击查看今日AI资讯早餐。
2025-01-17 11:05:25 -
![Claude 3.5突然上线,竟比GPT-4o还强!全新Artifacts改写模型交互]() Claude 3.5突然上线,竟比GPT-4o还强!全新Artifacts改写模型交互
Claude 3.5突然上线,竟比GPT-4o还强!全新Artifacts改写模型交互Anthropic曾许下要超越OpenAI的发家愿望,没想到竟然这么快就实现了。他们刚刚发布的Claude 3 5 Sonnet模型不仅成本更低、速度更快,而且在基准测试上的表现「弯道超车」GPT-4o。
2025-01-17 10:42:19 -
![快手「可灵」升级:新增图生视频与视频续写丨华为发布盘古大模型5.0丨腾讯元宝「AI搜索」能力升级]() 快手「可灵」升级:新增图生视频与视频续写丨华为发布盘古大模型5.0丨腾讯元宝「AI搜索」能力升级
快手「可灵」升级:新增图生视频与视频续写丨华为发布盘古大模型5.0丨腾讯元宝「AI搜索」能力升级【AI奇点网2024年6月24日早报】本站每日播报AI业界最新资讯,触摸时代脉搏,掌握未来科技动向。事不宜迟,点击查看今日AI资讯早餐。
2025-01-17 10:14:25 -
![苹果接触百度、阿里等多家中国AI公司洽谈大模型合作,国行iPhone AI能力有哪些?]() 苹果接触百度、阿里等多家中国AI公司洽谈大模型合作,国行iPhone AI能力有哪些?
苹果接触百度、阿里等多家中国AI公司洽谈大模型合作,国行iPhone AI能力有哪些?近日最新的消息指出,苹果已经与百度、阿里巴巴和百川智能等人工智能大模型的开发商进行了沟通,但目前还未达成最终协议。
2025-01-17 09:47:43 -
![OpenAI CTO穆拉蒂回应新一代模型:「GPT-5」今年没戏,一年半之后见]() OpenAI CTO穆拉蒂回应新一代模型:「GPT-5」今年没戏,一年半之后见
OpenAI CTO穆拉蒂回应新一代模型:「GPT-5」今年没戏,一年半之后见穆拉蒂表示,在接下来的几年里,我们期待ChatGPT在特定任务上达到「博士」的智力水平。事情正在飞速变化、改善。
2025-01-17 09:19:38








-
![怎么快速给模特换装_怎么用stable diffusion给模特换装]() 怎么快速给模特换装_怎么用stable diffusion给模特换装
怎么快速给模特换装_怎么用stable diffusion给模特换装本篇教程主要运用StableDiffusion这个工具来进行操作,下面会通过几个小案例,给大家展示不同需求下,我们该如何使用StableDiffusion来辅助我们完成服装效果展示。本教程适用于电商设计场景、摄影场景等多个运用人物设计的实战中
2024-12-23 13:57:15 -
![万万没想到,兵马俑都开始跳「科目三」:阿里云通义千问APP打造“全民舞王”视频创作工具,实测效果大赞]() 万万没想到,兵马俑都开始跳「科目三」:阿里云通义千问APP打造“全民舞王”视频创作工具,实测效果大赞
万万没想到,兵马俑都开始跳「科目三」:阿里云通义千问APP打造“全民舞王”视频创作工具,实测效果大赞兵马俑跳《科目三》,是我万万没想到的。有人借助了阿里云之前走红的AI视频生成技术——「Animate Anyone」,生成出来了这个舞蹈片段。
2024-12-13 16:46:26 -
![AIGC落地实践!四招帮你快速搞定运营设计]() AIGC落地实践!四招帮你快速搞定运营设计
AIGC落地实践!四招帮你快速搞定运营设计回顾这一年,随着 AIGC 浪潮的爆发,在掌握AI工具已经成为设计师必备技能。今天这篇文章,通过三个案例流程拆解带大家从新时代设计工作流,到必备「四大招式」,到图标设计六大方向,到训练专属模型,再到全流程手把手拆解设计项目,绝对干货满满
2024-12-18 16:57:17 -
ChatGPT怎么本地登录_GPT怎么使用_GPT本地项目
本期就ChatGPT的这次更新再次将完全新人使用指南提上日程,并对此次更新做些设想和想象。希望大家喜欢!
2024-12-19 07:41:20 -
![stable diffusion初识_stable diffusion跟其他工具有什么区别]]() stable diffusion初识_stable diffusion跟其他工具有什么区别]
stable diffusion初识_stable diffusion跟其他工具有什么区别]关于Stable Diffusion的内容很多,在本篇教程里,我会先为你介绍Stable Diffusion模型的运行原理、发展历程和相较于其他AI绘图应用的区别。
2024-12-24 13:45:31 -
![PikaAI怎么用_PIkaAI怎样生成视频_AI视频生成器Pika怎么用_AI视频生成工具Pika教程]() PikaAI怎么用_PIkaAI怎样生成视频_AI视频生成器Pika怎么用_AI视频生成工具Pika教程
PikaAI怎么用_PIkaAI怎样生成视频_AI视频生成器Pika怎么用_AI视频生成工具Pika教程Pika这款工具7月份在AIGC界横空出世,被圈内誉为目前“全球最好的文本生成视频AI工具”之一,也被认为是另外一款知名AI视频生成工具Runway的强有力挑战者。
2024-12-25 13:35:53 -
![如何使用 ChatGPT 调试代码]() 如何使用 ChatGPT 调试代码
如何使用 ChatGPT 调试代码当您的代码出现问题时,您可以向 ChatGPT 提供故障代码和问题描述。AI 工具将尝试识别并纠正问题。
2024-12-31 12:01:41 -
![stable SR脚本安装_stable diffusion脚本网站]() stable SR脚本安装_stable diffusion脚本网站
stable SR脚本安装_stable diffusion脚本网站上节课我们讲的4xUltraSharp是不是觉得已经很强了! 那么如果我拿出Stable SR脚本你应该如何应对呢?
2024-12-31 13:49:18 -
![怎么设置关键词权重_怎么设置Multi Prompts]() 怎么设置关键词权重_怎么设置Multi Prompts
怎么设置关键词权重_怎么设置Multi PromptsAI 绘画,顾名思义就是利用人工智能进行绘画,是人工智能生成内容(AIGC)的一个应用场景。其主要原理简单来说就是收集大量已有作品数据,通过算法对它们进行解析,最后再生成新作品,Midjourney是一个由同名研究实验室开发的人工智能程序。
2025-01-03 10:00:57 -
![零基础2天速成!白嫖「秋叶」官方AI绘画课程,卷死同事]() 零基础2天速成!白嫖「秋叶」官方AI绘画课程,卷死同事
零基础2天速成!白嫖「秋叶」官方AI绘画课程,卷死同事和「秋叶」一起学AI绘画,掌握Stable Diffusion、Midjourney的使用方法,开展AI绘画副业,搞钱!?
2024-12-17 12:53:01


![stable diffusion初识_stable diffusion跟其他工具有什么区别]](http://www.aituku.cc/uploadfile/2024/1224/d3a1bbf8bad6e281f82a2168727dfba1.png)