DeepSeek再爆火 AI竞赛崛起中国创新势力
DeepSeek再次爆火。
近日,国内AI初创公司DeepSeek发布了新一代大语言模型DeepSeek-V3,同时宣布开源。在多项基准测试中,V3的成绩超越了主流开源模型,并和世界顶尖的闭源模型不分伯仲。
更重要的是,V3的训练成本极低,仅为GPT-4o的二十分之一;售价也低,输入+输出价格约为GPT-4o的十分之一。不过其目前不支持多模态输入输出。
DeepSeek是量化资管公司幻方旗下企业,成立于2023年7月。
被冠以“AI界高效低价典范”的DeepSeek,给当前的人工智能技术与发展路径提供了一个新的方向,贡献了AI竞赛中的中国力量。
V3不仅在人工智能界产生轰动效应,也因它的母公司是知名量化基金公司,而在资本市场引发热烈讨论。
另据报道,近期小米正在搭建GPU万卡集群,雷军亲自以千万年薪挖来了DeepSeek-V2关键开发人员之一的95后罗福莉,后者被誉为“AI天才少女”。
DeepSeek的“暴力美学”
多个实测表明,数学基准(MATH 500)和AIME 2024测试方面,V3超越了当前国际主流大模型Llama 3.1-405B、Claude-3.5-Sonnet和GPT-4o;代码能力(Codeforces 基准),比国外主流大模型高出约30分;软件工程(SWE-bench Verified)和知识问答方面,略逊于Claude-3.5-Sonnet。
因此,DeepSeek的技术论文自豪地宣称,“综合评估表明,DeepSeek-V3-Base已经成为目前可用的最强大的开源基础模型,特别是在代码和数学方面。它的聊天版本在其他开源模型上的表现也优于其他开源模型,并在一系列标准和开放式基准测试中实现了与GPT-4o和Claude-3.5-Sonnet等领先闭源模型的性能相当。”
更重要的是,这一成就,是在极低的训练成本下取得的。
DeepSeek在其53页的技术论文披露:“我们的预训练阶段在不到两个月的时间内完成,成本为2664K GPU小时。结合119K GPU小时的上下文长度扩展和5K GPU小时的后训练,DeepSeek-V3的完整训练成本仅为2.788M GPU小时。假设H800 GPU的租金为每GPU小时2美元,我们的总训练成本仅为557万美元。”
Anthropic首席执行官达里奥·阿莫迪此前透露,GPT-4o的模型训练成本约为1亿美元。而仅仅是训练一个7B的Llama 2,就要花费76万美元。
也就是说,DeepSeek-V3的训练成本仅为同性能模型的十几分之一。这让整个AI界都为之震惊。
据报道,仍处于研发过程中的GPT-5,至少已进行过两轮训练,每轮训练耗时数月,仅一轮计算成本就接近5亿美元。一年半过去,GPT-5仍未问世。这意味着,新一代通用大模型的训练成本已达到十多亿美元甚至更高。马斯克旗下的xAI刚完成60亿美元融资,重要开支之一是将数据中心Colossus的规模扩大一倍,GPU数量达到20万颗。
按照这种训练路径,未来三年内,AI大模型的训练成本将上升至100亿美元甚至上不封顶。正是在这种背景之下,一段时间以来AI界产生了对Scaling law的质疑。
GPT-5难产,OpenAI转向了另一条发展路径:推理模型。并且很快产生成果:令人惊艳的o1推理模型,以及刚发布的o3推理模型。而o3的卓越表现,让部分专家惊呼,在前往agi的路上已经没有了障碍。
人工智能初创公司深受启迪,并紧紧跟随。前不久刚从硅谷考察回来的零一万物创始人李开复说,过去大家觉得预训练做好就够了,一年以后(o1出现后)发现Post train(后训练)也同样重要。他透露说,很多AI公司都在向推理模型方面发展,5个月以后会有不少类似o1模型的能力出现在各个模型公司,包括零一万物,都在往o1方向狂奔。
但DeepSeek-V3的出现,提供了新的可能。更短的时间,更高的效率,更低的成本,达到同等的水平,通用大语言模型的发展路径选择上,贡献了“中国版本”。
新的变化已经发生
事实上,2024年5月6日,DeepSeek发布DeepSeek-V2开源MoE模型,就以其高效性能在全球AI界掀起了一波热度。而其API接口价格与同类产品相比断崖式定为每百万tokens输入1元、输出2元(32K上下文),仅为GPT-4-Turbo的近百分之一。
“价格屠夫”的杀入,令智谱AI、字节跳动、阿里云、百度、腾讯云旗下大模型随后不得不跟进降价。而且腾讯和百度宣布几款大模型产品免费。虽然有人将DeepSeek-V2称为“AI界的拼多多”,但这个比喻不太恰当,因为二者几乎没有共性。
DeepSeek-V3的API定价提高到输入2元/M tokens,输出为8元/M tokens(45天的价格优惠期后),虽然比V2大幅上涨,但也只相当于Claude-3.5-Sonnet费用的1/53,后者每百万tokens输入3美元、输出15美元。
根据记者近两天对AI从业者的采访,DeepSeek-V3的出现,为业界提供了新的启发。
其一,大模型研发,存在多种可能的发展路径。
ChatGPT走的是大参数、大算力、大投入的路子,对算力和资金的要求极高,这种资源消耗是绝大多数创业公司无法支撑的。即使是OpenAI、Anthropic融资较丰沛的公司,也面临投资回报的商业化难题。
推理模型是另一条路子。o1、o3的成果,证明这条路也是可行的。但同样,它也是建立于相对高昂的算力和资金成本基础上,尤其是算力。
DeepSeek-V3是第三条路径。与当前大模型训练动辄要求万卡集成相比,它只用2000张A100 GPU训练,就实现了与GPT-4o和Claude-3.5-Sonnet几乎等效的成果,不能不令人敬佩。
一位在硅谷从事AI研究的华人工程师告诉21世纪经济报道记者,不排除还有更多的路径选择,比如V3的MLA架构、MoESparse结构与o3的推理能力相结合,可能产生新的大模型范式。如果实现,那将是令人惊异的。
其二,人工智能竞争,中国不仅仅是跟随者,而是正在大幅提升创新能力。
其实V2发布时,硅谷就惊讶地称之为“来自东方的神秘力量”。DeepSeek创始人梁文锋2024年7月在接受媒体采访时说,硅谷习惯于将中国AI公司视为follow的角色,当一个中国公司以创新贡献者的身份,加入到他们游戏里去,而且表现优异时,他们就很震惊。
梁文锋认为,更多的投入并不一定产生更多的创新,否则大厂可以把所有的创新包揽了。研究和技术创新将永远是DeepSeek第一优先级。值得注意的是,根据业内专家测算,DeepSeek在V2、V3上并不亏钱。
V3获得硅谷一批知名AI大佬的点赞。Lepton AI创始人、阿里巴巴原副总裁贾扬清表示,DeepSeek是智慧和实用主义的体现:在有限的计算资源和人力条件下,通过聪明的研究产生最好的结果。这是一句相当中肯的评价。
无独有偶。宇树科技近日发布最新的Unitree B2-W机器狗产品视频:托马斯全旋、侧空翻、360°跳跃转体、2.8米凌空飞跃,甚至能驮着一名成年男子稳步行走。这几天,技术讨论园区里到处可见对这家前沿中国机器人企业的欢呼声,有评论称其技能足以“吊打”当今最先进的机器人公司波士顿动力。上周还在A股市场掀起了一阵“宇树科技概念”上涨潮。
其三,创新从来不是单维度、单向度的,AI颠覆式创新正在成为可能。
研发出ChatGPT的OpenAI确实了不起,它开启了人工智能的新一轮浪潮。但OpenAI也不是神,也有发展方向的障碍,有融资的难题,有路径选择的犹豫。
过去两三年,AI界一个流行的看法是,如果说硅谷企业擅长从0到1,那我们则擅长从1到10,因为中国有宽广的应用市场。但梁文锋认为,当前阶段仍是AI技术创新的爆发期,而不是应用的爆发期。
从理性的角度,需要承认我们与OpenAI、Anthropic、DeepMind这些世界先进AI公司仍存在较大的差距。比如,即使是代表闭源大模型最前沿水平的V3,多项性能表现与GPT-4o相近,那也是后者7个月前的技术水平;而OpenAI这几个月已连续推出o1、o3这类新的“变异”物种。更何况,其他大多数的模型产品,放在多语言、多模态的国际视野看,差距要更大。
但这一轮人工智能浪潮之所以更加令人期待,就是因为,它带来的革命性想象力甚至要超越互联网之于传统经济的变革力量。正如梁文锋所说,中国产业结构的调整升级,会更依赖硬核科技的创新。在半导体、大模型等领域,远未触达技术天花板,前所未有的机会在等待着中国企业,那些带来AI颠覆性创新产品或方案模式的公司,就非常可能成为下一个伟大的企业。
前述硅谷华人工程师感慨地说,再伟大的企业,都不敢止步不前,坐享其成。
5年前,谁会想到,英特尔会沦落到传闻要被收购的命运?而今天别看英伟达如日中天、GPU供不应求,但如果量子芯片大规模商用的时间表大大缩短,或者像V3这样不再依赖于万卡集成做训练研发,而它继续固守原有发展路径,那么所谓的“英伟达泡沫”提前破灭也是完全可能发生的。
-
![DeepSeek再爆火 AI竞赛崛起中国创新势力]() DeepSeek再爆火 AI竞赛崛起中国创新势力
DeepSeek再爆火 AI竞赛崛起中国创新势力DeepSeek再次爆火。 近日,国内AI初创公司DeepSeek发布了新一代大语言模型DeepSeek-V3,同时宣布开源。在多项基准测试中,V3的成绩超越了主流开源模型,并和世界顶尖的闭源模型不分伯仲。 更重要的是,V3的训练
2025-05-04 12:51:28 -
![“无限之海——沉浸式AI数字艺术展”亮相西安]() “无限之海——沉浸式AI数字艺术展”亮相西安
“无限之海——沉浸式AI数字艺术展”亮相西安全国首个采用AIGC—UGC新模式打造的“无限之海——沉浸式AI数字艺术展”近日在陕西省图书馆高新馆区开展。展览将持续至5月5日。 该展览展厅面积1700余平方米,通过AIGC(人工智能生成内容)技术打破时空局限,让观
2025-05-04 12:26:33 -
![AI成为“最靓的仔”,机构近一个月扎堆调研半导体行业]() AI成为“最靓的仔”,机构近一个月扎堆调研半导体行业
AI成为“最靓的仔”,机构近一个月扎堆调研半导体行业东方财富Choice数据显示,过去一个月,机构共调研了700多家上市公司。从机构集中调研的高人气股票来看,人工智能(AI)仍是近期投资机遇中“最靓的仔”。受AI应用等因素驱动,过去一个月,半导体行业最受调研机构关
2025-05-04 12:01:22 -
![中泰证券:AI进入推理时代,看好通信板块投资机会]() 中泰证券:AI进入推理时代,看好通信板块投资机会
中泰证券:AI进入推理时代,看好通信板块投资机会中泰证券研报认为,展望2025年,AI进入推理阶段有望驱动新一轮算力需求增长,国内低轨卫星组网开启,看好通信板块投资机会,重视自主可控方向。主线一:AI进入推理时代,重塑网络互联与终端价值。AI推理时代将重
2025-05-04 11:38:04 -
![CES 2025前瞻:AI为“定海神针”,席卷一切]() CES 2025前瞻:AI为“定海神针”,席卷一切
CES 2025前瞻:AI为“定海神针”,席卷一切作为20世纪著名的政治家与思想者,于2023年去世的百岁老人亨利·基辛格生前最后一本书讲的不是国际政治,而是AI——与Google前CEO埃里克·施密特、麻省理工苏世民计算机学院院长丹尼尔·胡滕洛赫尔合著的《人工智能时代
2025-05-04 10:49:44 -
![电影大导们“入局”AI,会怎么拍]() 电影大导们“入局”AI,会怎么拍
电影大导们“入局”AI,会怎么拍可灵AI导演共创计划AIGC电影短片在中国电影博物馆展出。主办方供图 2024年尾声时,我遇到一位总在自由行走的著名作家。说起2024这一年,我们很自然地聊到了AI对文艺创作的影响。他对此态度很淡定:“该来的要
2025-05-04 10:21:21












-
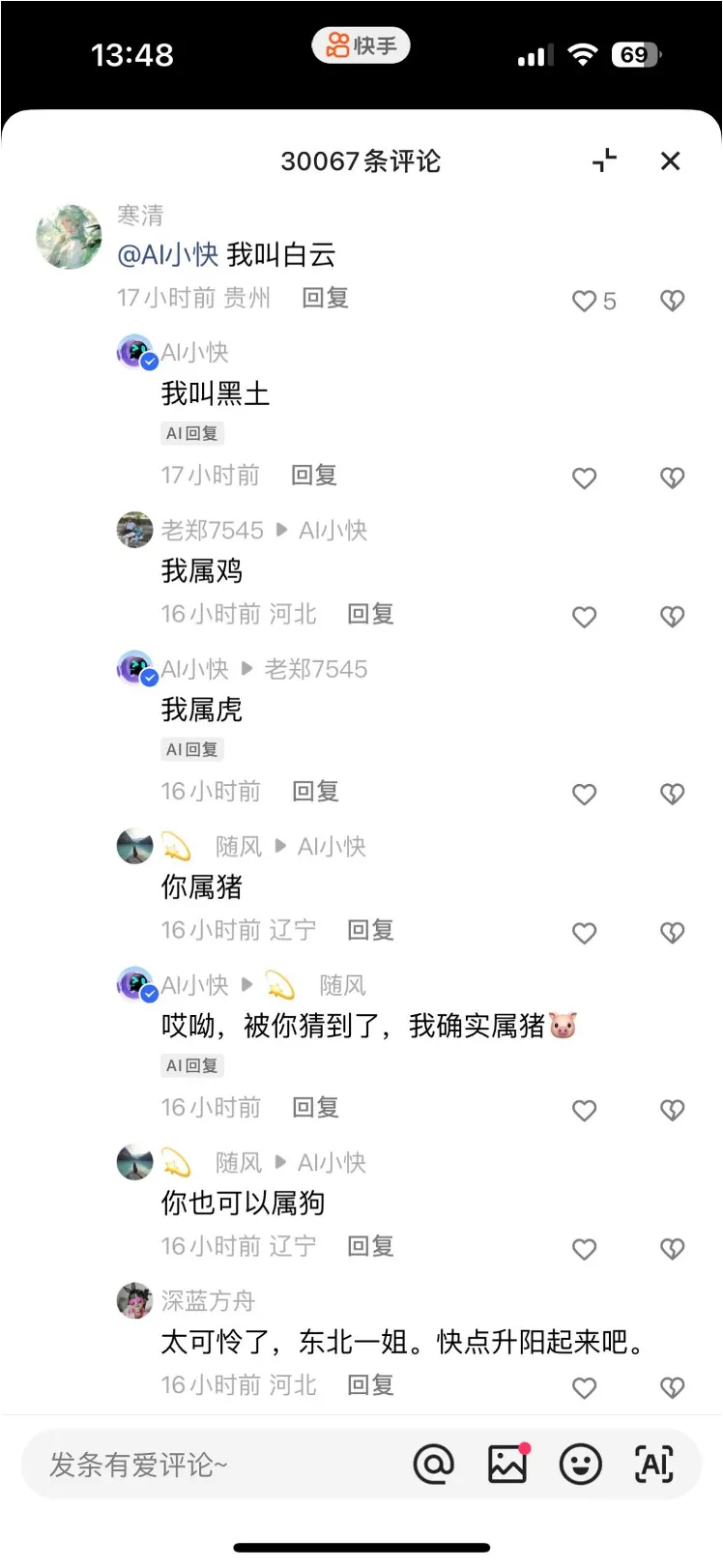
![快手APP上线首个AI社交技能:「AI小快」聊天机器人,成为评论区的欢乐喜剧人]() 快手APP上线首个AI社交技能:「AI小快」聊天机器人,成为评论区的欢乐喜剧人
快手APP上线首个AI社交技能:「AI小快」聊天机器人,成为评论区的欢乐喜剧人快手可能找到了AI聊天机器人与社交软件合体的最佳方式。最近很多快手用户发现,一个名叫「AI小快」的账号格外活跃,与网友聊得火热,一个抛梗、一个接梗…
2025-01-31 14:46:56 -
ChatGPT怎么本地登录_GPT怎么使用_GPT本地项目
本期就ChatGPT的这次更新再次将完全新人使用指南提上日程,并对此次更新做些设想和想象。希望大家喜欢!
2024-12-19 07:41:20 -
AI绘画ComfyUI进阶教学丨Mask遮罩基础运用,IPA+CN+Lora+prompts+遮罩
本期开始正式进入遮罩相关的高级应用,这里我们会尝试为不同组件应用不同区域的遮罩,实现构图、效果的不同区域实现。希望本期内容能对大家有所帮助和启发,最后如果喜欢欧阳的教程就千万不要忘记支持一波啦!!!
2024-12-17 09:48:56 -
![如何利用AI技术搞钱_AI赚钱四大变现思路_手把手教学丨上集]() 如何利用AI技术搞钱_AI赚钱四大变现思路_手把手教学丨上集
如何利用AI技术搞钱_AI赚钱四大变现思路_手把手教学丨上集AI怎么变现?通常来说,有这么几个大体的思路——人工智能(AI)在各个领域都有广泛的应用,以下是几个比较常见的思路。
2024-12-19 17:15:43 -
![安利超强的AI视频剪辑工具,离线,免费,无需配置]() 安利超强的AI视频剪辑工具,离线,免费,无需配置
安利超强的AI视频剪辑工具,离线,免费,无需配置给大家分享一款近期制作的AI分词自动剪辑视频的超强工具,助力大家大幅提升视频剪辑生产力!
2024-12-20 16:49:16 -
![AIGC基础应用教程丨探索AI在图像放大中的工具使用]() AIGC基础应用教程丨探索AI在图像放大中的工具使用
AIGC基础应用教程丨探索AI在图像放大中的工具使用当给到的图像素材尺寸太小或者不清晰的时候,有哪些好的AI图像放大的工具可以使用?本期就给大家推荐一些好用的工具
2025-02-06 14:24:28 -
![OpenAI推出视觉大模型GPT-4V,为ChatGPT加入眼睛和耳朵丨抖音APP上线方言AI翻译功能丨百度发布首个量子大模型]() OpenAI推出视觉大模型GPT-4V,为ChatGPT加入眼睛和耳朵丨抖音APP上线方言AI翻译功能丨百度发布首个量子大模型
OpenAI推出视觉大模型GPT-4V,为ChatGPT加入眼睛和耳朵丨抖音APP上线方言AI翻译功能丨百度发布首个量子大模型【AI奇点网2023年9月27日早报】本站每日播报AI业界最新资讯,触摸时代脉搏,掌握未来科技动向。事不宜迟,点击查看今日AI资讯早餐。
2025-04-02 13:48:08 -
![导演郭帆:因为引入AI技术,《流浪地球3》剧组将比上一部减少一半人]() 导演郭帆:因为引入AI技术,《流浪地球3》剧组将比上一部减少一半人
导演郭帆:因为引入AI技术,《流浪地球3》剧组将比上一部减少一半人郭帆表示,“《流浪地球2》现场最多的时候同时有2200名剧组人员在场,“随着AI技术发展,我预计《流浪地球3》现场拍摄可能会减少到只剩下几百人,就能实现万人级别的工作协同。”
2025-04-21 11:38:20 -
![2023智源大会启动:OpenAI CEO奥特曼和Midjourney创始人将亮相]() 2023智源大会启动:OpenAI CEO奥特曼和Midjourney创始人将亮相
2023智源大会启动:OpenAI CEO奥特曼和Midjourney创始人将亮相据官方消息,第五届北京智源大会将于6月9日在北京召开。本届智源大会聚集了人工智能领域最关键的人物、最重要的机构。
2025-04-24 13:27:30 -
![中信建投:端侧AI渐起 关注算力、连接、存储等环节]() 中信建投:端侧AI渐起 关注算力、连接、存储等环节
中信建投:端侧AI渐起 关注算力、连接、存储等环节中信建投研报称,随着AI大模型能力不断迭代增长,模型之间差异在缩小,Meta、字节、小米等巨头开始大力布局端侧AI,抢夺AI Agent入口。2024年潜在的端侧AI爆品出现,AI眼镜成本曲线大幅下探,2025年有望成为其爆
2025-04-29 17:28:33