智源大会产品之一“悟道·视界”:点亮国内绘画通用模型科技树
AI奇点网6月9日报道 | 转载自智东西
除了发布开源语言大模型及评测体系外,智源研究院还一连发布了“悟道·视界”视觉大模型系列的6项先进技术成果。
据黄铁军分享,从技术路线而言,通用视觉模型与语言模型的方法论类似,但视觉涌现与语言涌现的形式有所差别。传统视觉模型属于判别式模型,通用视觉模型则更看重对未知事物的通用辨别能力和生成预测能力。
“悟道·视界”由悟道3.0的视觉大模型团队打造,是一套具备通用场景感知和复杂任务处理能力的智能视觉和多模态大模型系列。6项国际领先技术中,前5个是基础模型,最后1个是应用技术。
1、Emu:在多模态序列中补全一切的多模态大模型Emu是一个多模态-to-模态的大模型,输入输出均可为多模态,可以接受和处理不同模态的数据,并输出各类的多模态数据。
基于多模态上下文学习技术路径,Emu能从图文、交错图文、交错视频文本等海量多模态序列中学习。训练完成后,Emu能在多模态序列的上下文中补全一切,也就是可通过多模态序列做prompting(提示),对图像、文本和视频等多种模态的数据进行感知、推理和生成。

相比其他多模态模型,Emu能进行精准图像认知,完成少样本图文理解,根据图片或者视频进行问答和多轮对话。它也具备文图生成、图图生成、多模态上下文生成等生成能力。
2、EVA:最强十亿级视觉基础模型如何让通用视觉模型兼顾更高效和更简单?抓住语义学习和几何结构学习这两个关键点,基本可以解决绝大部分的视觉任务。

智源的十亿级视觉基础模型EVA便将最强语义学习(CLIP)与最强几何结构学习(MIM)结合,再将标准的ViT模型扩大规模至10亿参数进行训练,一举在ImageNet分类、COCO检测分割、Kinetics视频分类等广泛的视觉感知任务中取得当时最强性能。
论文地址:
https://arxiv.org/abs/2211.07636
代码地址:
https://github.com/baaivision/EVA
3、EVA-CLIP:性能最强开源CLIP模型EVA-CLIP基于通用视觉模型EVA开发,相关工作入选2023 CVPR Highlight论文。 EVA极大地稳定了巨型CLIP的训练和优化过程,仅需使用FP16混合精度,就能帮助训练得到当前最强且最大的开源CLIP模型。

此前多模态预训练模型CLIP作为零样本学习基础模型,广受业界认可。智源视觉团队在今年年初发布的EVA-CLIP 5B版本,创造了零样本学习性能新高度,超越了此前最强的Open CLIP模型,在ImageNet1K零样本top1达到最高的82.0%准确率。此外,智源去年发布的EVA-CLIP 1B版本,今年才被Meta发布的DINOv2模型追平ImageNet kNN准确率指标。
论文地址:
https://arxiv.org/abs/2303.15389
代码地址:
https://github.com/baaivision/EVA/tree/master/EVA-CLIP
4、Painter:首创“上下文图像学习”技术路径的通用视觉模型研究者相信,表达图像信息最好的方式就是图像,图像理解图像、图像解释图像、图像输出图像,可以避免图像-语言翻译过程中产生的信息误差和成本消耗。
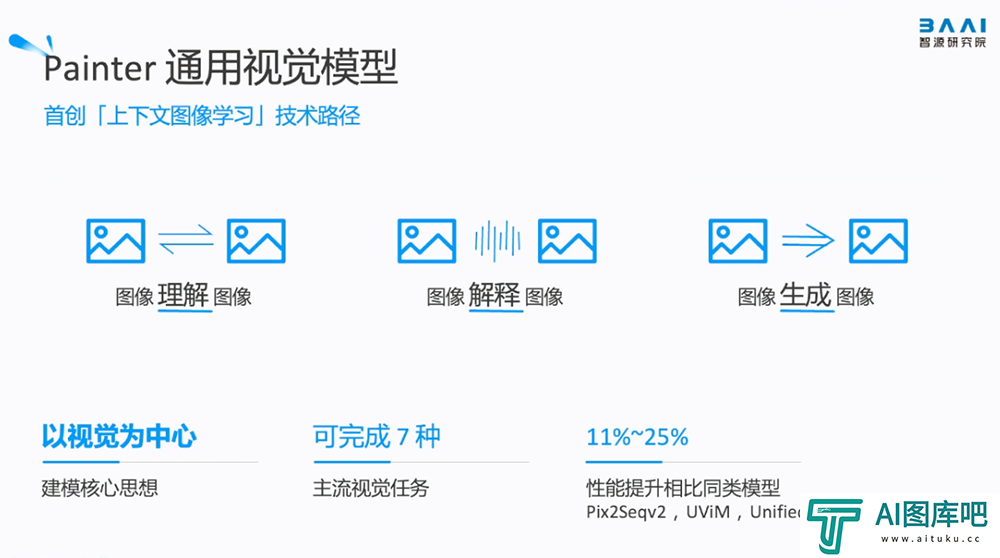
智源将NLP中的上下文学习概念引入视觉模型,打造了将“以视觉为中心”作为建模核心思想的通用视觉模型Painter。Painter把图像作为输入和输出,从而获得了上下文视觉信息,完成不同的视觉任务。该模型目前可完成7种主流视觉任务,已在深度估计、语义分割等核心视觉任务中,相比同类模型有11%~25%的性能提升。
论文地址:
https://arxiv.org/abs/2212.02499
代码地址:
https://github.com/baaivision/Painter
5、视界通用分割模型:一通百通,分割一切从影像中分割出各种各样的对象,是视觉智能的关键里程碑。今年年初,智源研发的首个利用视觉提示(prompt)完成任意分割任务的“视界通用分割模型”,与Meta的SAM模型同时发布,点亮了通用视觉GPT曙光。

“视界通用分割模型”具有强大的视觉上下文推理能力:给出一个或几个示例图像和意图掩码(视觉提示prompt),模型就能理解用户意图,“有样学样”地完成类似分割任务。用户在画面上标注识别一类物体,即可批量化识别分割同类物体。此外,该模型还具备强大的通用能力、灵活推理能力和自动视频分割与追踪能力。
论文地址:
https://arxiv.org/abs/2304.03284
代码地址:
https://github.com/baaivision/Painter
Demo地址:
https://huggingface.co/spaces/BAAI/SegGPT
6、vid2vid-zero:首个零样本视频编辑方法现有文本驱动的AIGC视频编辑方法严重依赖于大量“文本-视频”数据上调整预训练好的视频扩散模型,需要庞大的计算资源,带来了高昂的人工数据标注成本和计算成本。

智源研究院提出的零样本视频编辑方法vid2vid-zero,首次在无需额外视频训练的情况下,利用注意力机制动态运算的特点,结合现有图像扩散模型,实现可指定属性的视频编辑。只需上传视频,输入一串编辑文本提示,就可以坐等AI创作出创意视频。
论文链接:
https://arxiv.org/pdf/2303.17599.pdf
代码地址:
https://github.com/baaivision/vid2vid-zero
Demo地址:
https://http://huggingface.co/spaces/BAAI/vid2vid-zero
“悟道·视界”聚焦视觉和多模态上下文学习,创新了视觉和多模态领域的Prompt工程,取得了零样本学习性能的新突破。未来其应用可带给自动驾驶、智能机器人等领域更多可能性。还有多语言AIGC文图生成,通用智能体学习等多模态领域,也将公布相关代码。
-
![智源大会产品之一“悟道·视界”:点亮国内绘画通用模型科技树]() 智源大会产品之一“悟道·视界”:点亮国内绘画通用模型科技树
智源大会产品之一“悟道·视界”:点亮国内绘画通用模型科技树“悟道·视界”由悟道3 0的视觉大模型团队打造,是一套具备通用场景感知和复杂任务处理能力的智能视觉和多模态大模型系列。6项国际领先技术中,前5个是基础模型,最后1个是应用技术。
2025-04-24 14:12:31 -
![周鸿祎:360智脑AI押宝高考作文题10中2,AI写出来的作文没有灵魂]() 周鸿祎:360智脑AI押宝高考作文题10中2,AI写出来的作文没有灵魂
周鸿祎:360智脑AI押宝高考作文题10中2,AI写出来的作文没有灵魂周鸿祎发微博表示,有网友用360智脑押宝高考的作文题,十道里押中两次,分别是全国甲卷和新课标2卷。
2025-04-24 13:48:07 -
![2023智源大会启动:OpenAI CEO奥特曼和Midjourney创始人将亮相]() 2023智源大会启动:OpenAI CEO奥特曼和Midjourney创始人将亮相
2023智源大会启动:OpenAI CEO奥特曼和Midjourney创始人将亮相据官方消息,第五届北京智源大会将于6月9日在北京召开。本届智源大会聚集了人工智能领域最关键的人物、最重要的机构。
2025-04-24 13:27:30 -
![科技部下属智源研究院举办AI峰会:奥特曼亮相丨ChatGPT for iPad应用发布丨张颂文谈AI换脸]() 科技部下属智源研究院举办AI峰会:奥特曼亮相丨ChatGPT for iPad应用发布丨张颂文谈AI换脸
科技部下属智源研究院举办AI峰会:奥特曼亮相丨ChatGPT for iPad应用发布丨张颂文谈AI换脸【AI奇点网2023年6月9日早报】本站每日播报AI业界最新资讯,触摸时代脉搏,掌握未来科技动向。事不宜迟,点击查看今日AI资讯早餐。
2025-04-24 13:01:06 -
![《狂飙》反派男一号张颂文谈AI换脸技术:深感震惊,AI演戏没有人情味]() 《狂飙》反派男一号张颂文谈AI换脸技术:深感震惊,AI演戏没有人情味
《狂飙》反派男一号张颂文谈AI换脸技术:深感震惊,AI演戏没有人情味日前,知名演员张颂文在一次公开活动上分享自己对AI换脸的思考。坦言在看到一则AI合成的表演短视频后,自己整个人都失眠了。
2025-04-24 12:40:16 -
![似乎没有它办不到的事:荷兰瑞士团队使用ChatGPT设计出机器人]() 似乎没有它办不到的事:荷兰瑞士团队使用ChatGPT设计出机器人
似乎没有它办不到的事:荷兰瑞士团队使用ChatGPT设计出机器人近日,荷兰代尔夫特理工大学和瑞士洛桑联邦理工学院的研究人员试图让ChatGPT设计一个机器人,并将研究结果发表在《自然机器智能》上。
2025-04-24 12:14:14











-
AI绘画ComfyUI进阶教程丨如何实现Clip精准控图,流程自动化入门!
大家好,又到学习时刻? 本期跟大家分享CLIP构图相关的一些进阶基础内容,以及自动化逻辑编程基础,希望能对大家有所启发,最后不要忘记支持欧阳一波啦?!
2024-12-17 13:16:14 -
![阿里寻光_寻光视频创作平台_寻光视频创作官方网站]() 阿里寻光_寻光视频创作平台_寻光视频创作官方网站
阿里寻光_寻光视频创作平台_寻光视频创作官方网站AIGC时代,视频创作这事儿真的不一样了。就像这样,轻轻一圈,选定目标立刻变身单独图层,再丝滑嵌入不同的背景视频,场景变换so easy~
2025-01-16 11:04:19 -
![有手就行:Stability AI推出简笔画生成图片工具Stable Doodle]() 有手就行:Stability AI推出简笔画生成图片工具Stable Doodle
有手就行:Stability AI推出简笔画生成图片工具Stable Doodle近日,图像生成模型 Stable Diffusion 背后的初创公司 Stability AI 推出了一项新的服务,可以将简笔画转换为图像。这项服务名为 Stable Doodle,利用最新的 Stable Diffusion 模型分析简笔画的轮廓,让每个人都能得到堪称艺术的作品。
2025-04-10 13:09:46 -
![AI动漫视频生成_yoyo官方网站_yoyo功能及介绍]() AI动漫视频生成_yoyo官方网站_yoyo功能及介绍
AI动漫视频生成_yoyo官方网站_yoyo功能及介绍视频生成赛道又起新秀,而且还是二次元定制版!稳定产出电影级画面,一键文 图生成视频,即使是「手残党」也能复刻自己喜欢的动漫作品了。
2025-01-16 11:53:08 -
![阿里云通义千问上线AIGC春节新玩法:AI帮你免费拍摄全家福,AI舞蹈视频生成器“全民舞王”新增春晚舞蹈]() 阿里云通义千问上线AIGC春节新玩法:AI帮你免费拍摄全家福,AI舞蹈视频生成器“全民舞王”新增春晚舞蹈
阿里云通义千问上线AIGC春节新玩法:AI帮你免费拍摄全家福,AI舞蹈视频生成器“全民舞王”新增春晚舞蹈春节将至年味渐浓,阿里云通义千问APP上线多项免费新应用,涵盖全家福、拜新年、万物成龙等图像生成的新玩法。
2025-02-13 15:39:26 -
![应用商店下载排行第一,“Meta版推特”Threads注册用户超5000万]() 应用商店下载排行第一,“Meta版推特”Threads注册用户超5000万
应用商店下载排行第一,“Meta版推特”Threads注册用户超5000万新上线社交应用Threads已注册激活用户超过5000万,该数字仍在持续增长。当前在英国和美国苹果应用商店免费应用中的下载量排名第一。
2025-04-14 13:36:13 -
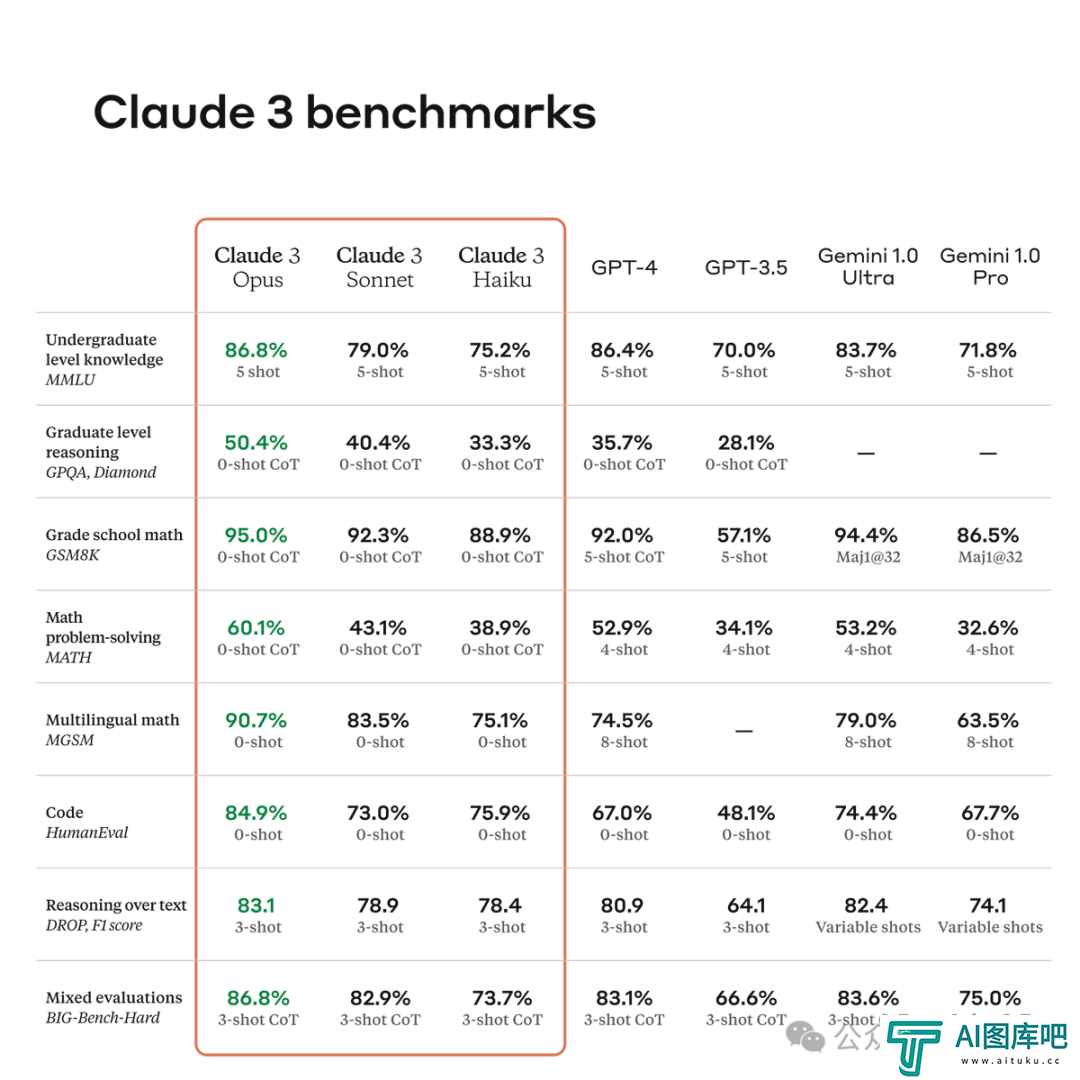
![大语言模型「新王」Claude 3全面测评:原生多模态大模型各项能力实力超群,连打麻将都学会,实测比GPT-4好用]() 大语言模型「新王」Claude 3全面测评:原生多模态大模型各项能力实力超群,连打麻将都学会,实测比GPT-4好用
大语言模型「新王」Claude 3全面测评:原生多模态大模型各项能力实力超群,连打麻将都学会,实测比GPT-4好用OpenAI「不可战胜」的神话,看样子是要被打破了。Claude 3的多版本发布后,“中杯”Sonnet直接免费体验,“大杯”Opus充个会员也能即刻享受,各路测评纷至沓来。
2024-12-13 18:57:45 -
![AI写真生成器妙鸭相机免费体验版实测_仅需8张自拍]() AI写真生成器妙鸭相机免费体验版实测_仅需8张自拍
AI写真生成器妙鸭相机免费体验版实测_仅需8张自拍在小红书、朋友圈刷屏的“妙鸭相机”,还记得吗?9月20日,这家AI快消应用公司宣布“妙鸭相机”免费体验版本正式上线啦!本次更新的“妙鸭相机”APP,专业版要求上传的图片数量也从20张下调到15张了哟
2024-12-16 09:21:10 -
![网易出品的免费AI在线绘画工具:AI绘画工坊,安利给大家]() 网易出品的免费AI在线绘画工具:AI绘画工坊,安利给大家
网易出品的免费AI在线绘画工具:AI绘画工坊,安利给大家网易出品推出的云端Stable Diffusion简直太好用了,集成了多种模型任你选,想生成什么类型的图像都超级容易。
2024-12-16 09:26:04 -
AI绘画ComfyUI进阶教程丨插件IPAdapter的详细使用教程,风格模仿,换脸全靠它
哈咯大家好,本期正式给大家带来进阶部分的插件讲解教程,虽然很多朋友一直在用IPA但可能很多朋友还不太了解其结构,希望这期关于ipa用法的教程能对大家有所帮助吧!
2024-12-17 22:49:30