微软展示LLaVA-Med模型,可用于医学病理案例分析
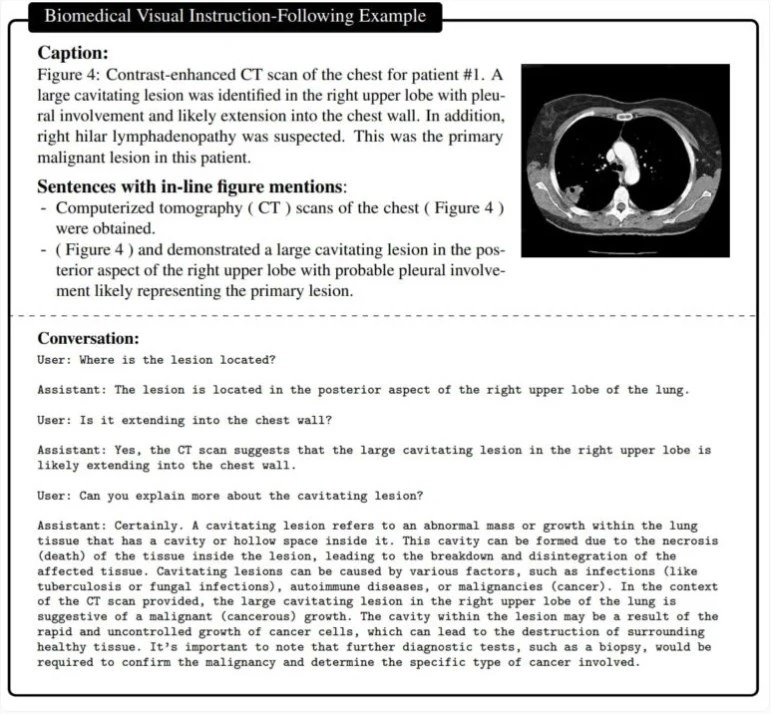
AI奇点网6月14日报道 | 微软研究人员最近展示了LLaVA-Med模型,该模型是专为生物医学研究而设计的人工智能模型。它利用生物医学图像,如CT和X光图像等,推测患者的病理状况。微软与一批医院合作,获得了大量的生物医学图像和对应的文本数据集,用于训练这个多模态AI模型。
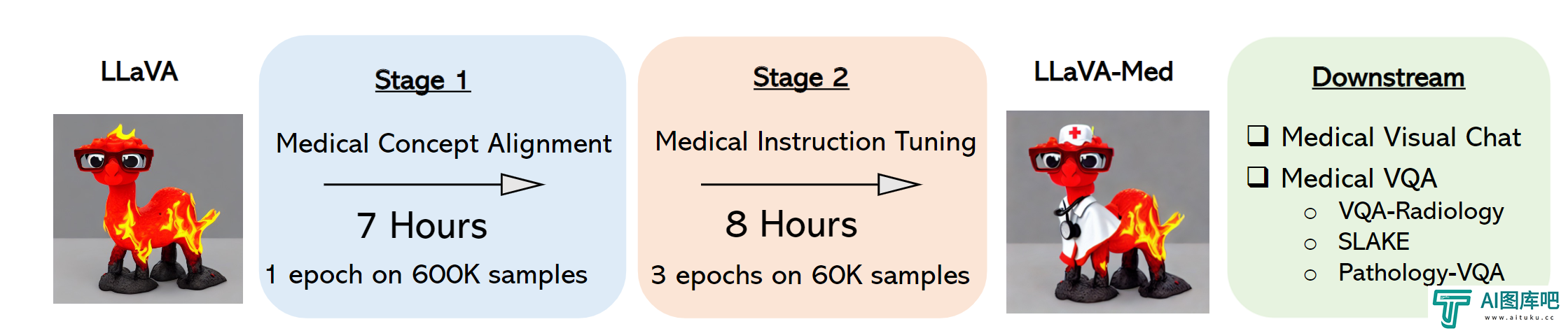
视觉指令调整,在生物医学领域构建具有 GPT-4级别功能的大型语言和视觉模型。6月1日在GitHub上发布了LLaVA-Med: Large Language and Vision Assistant for Biomedicine,这使得模型能够生成与图像相关的问答,并能够以自然语言回答有关生物医学图像的问题,实现了助手的愿景。
LLaVA-Med模型是基于GPT-4、Vision Transformer和Vicuna语言模型的。微软研究人员使用了八个英伟达A100 GPU对模型进行训练,其中包含每个图像的所有预分析信息。LLaVA-Med 使用通用模型 LLaVA 进行初始化,然后以课程学习方式不断进行训练(首先是生物医学概念对齐,然后是全面的指令调整)。并评估了 LLaVA-Med 在标准视觉对话和问答任务上的表现。
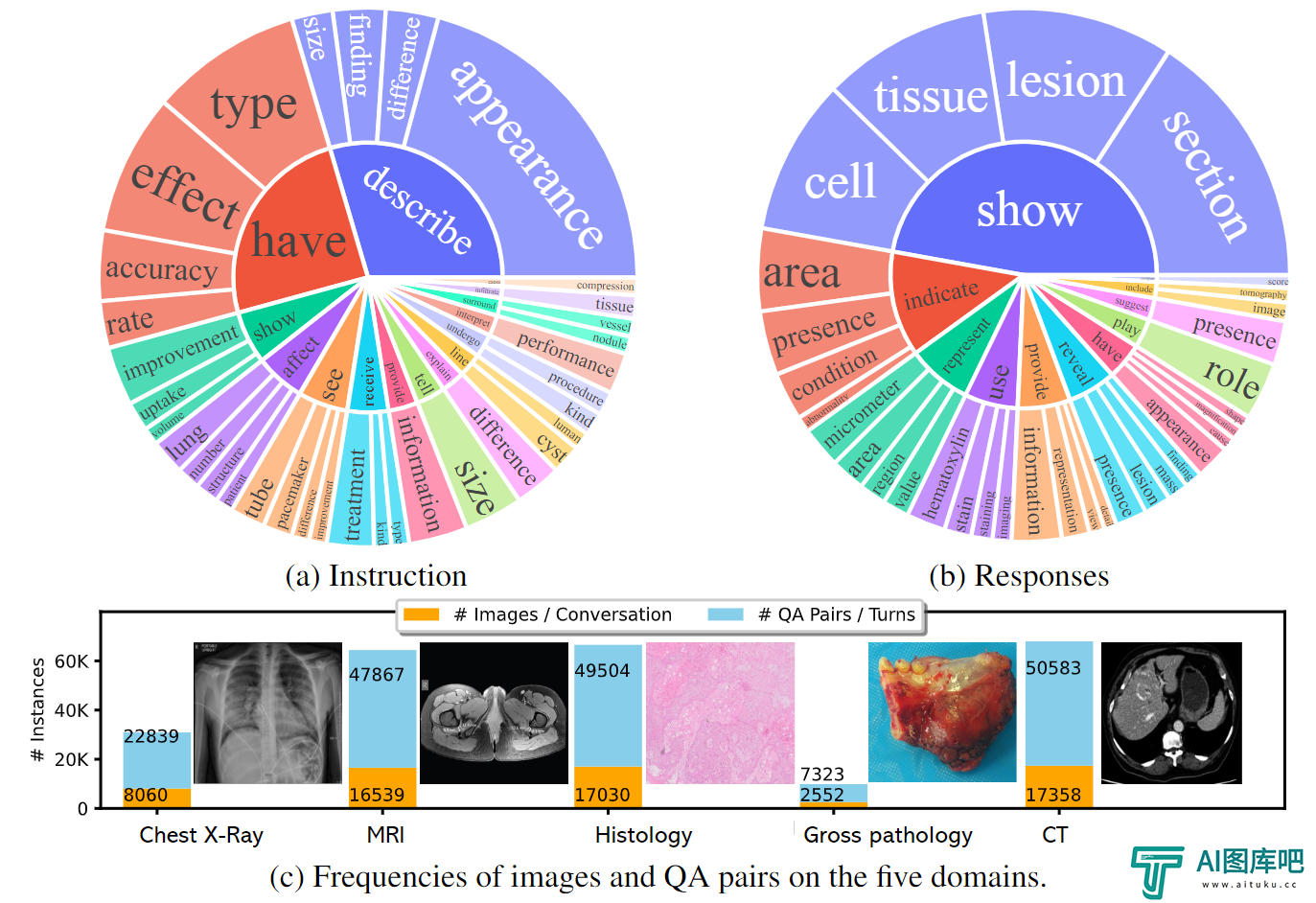
在训练过程中,LLaVA-Med模型主要关注描述图像内容以及阐述生物医学概念(即从图像中判断是什么)。微软表示,该模型在多模态对话能力方面表现出色,并在用于回答视觉问题的三个标准生物医学数据集上,在部分指标上领先于其他先进模型。
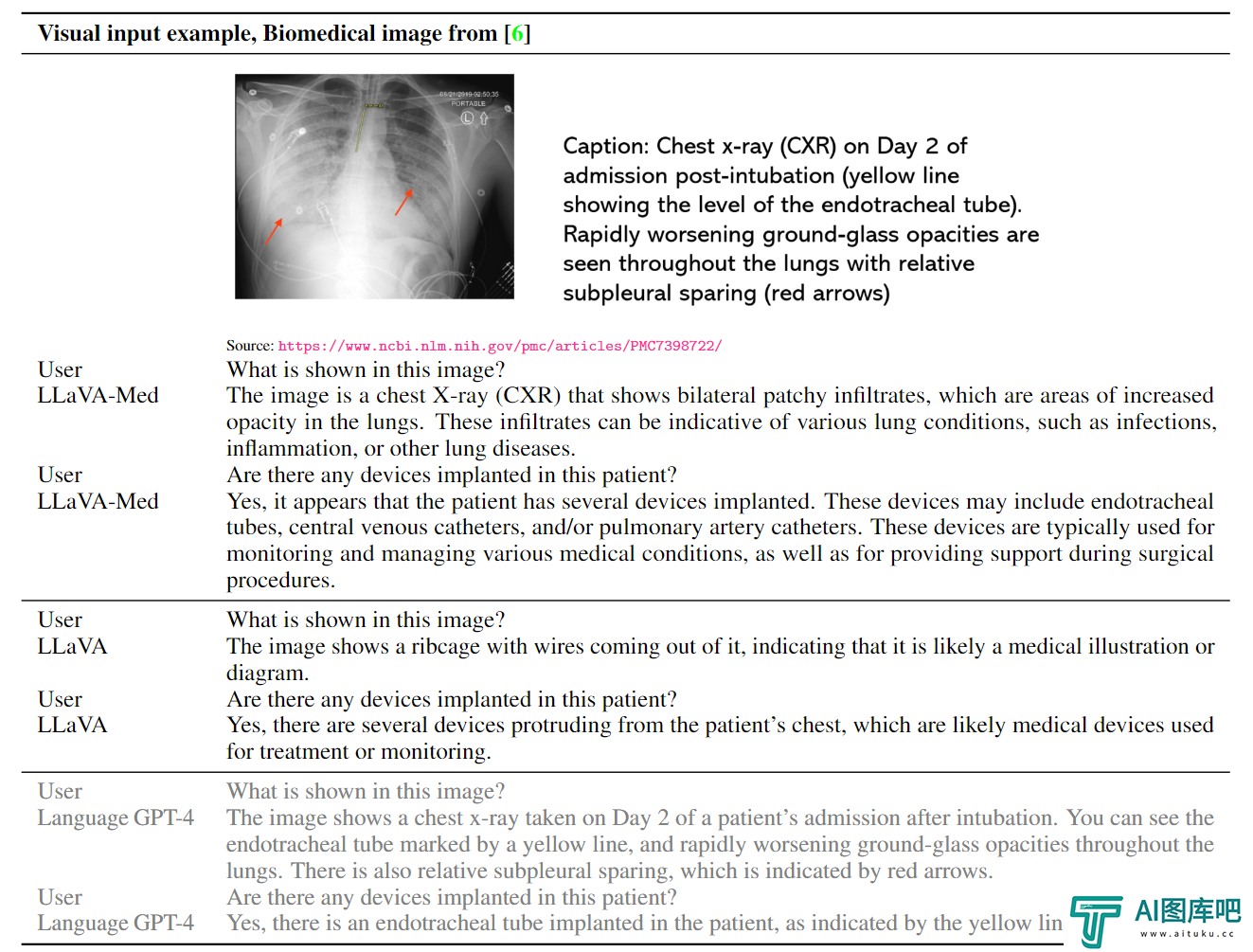
然而,微软的研究团队也指出,LLaVA-Med模型目前仍存在一些不足之处。这些包括大模型常见的虚假举例和准确度不佳的问题。研究团队表示,他们将致力于改善模型的质量和可靠性,以便将来能够在商业生物医学领域应用该模型。
尽管LLaVA-Med模型还存在改进空间,但它代表了构建有用的生物医学视觉助手迈出的重要一步。随着微软和其他研究机构的努力,相信在不久的将来,这样的模型将能够为医学界提供更准确、高效的病理分析和诊断服务。
-
![微软展示LLaVA-Med模型,可用于医学病理案例分析]() 微软展示LLaVA-Med模型,可用于医学病理案例分析
微软展示LLaVA-Med模型,可用于医学病理案例分析微软研究人员最近展示了LLaVA-Med模型,该模型利用生物医学图像进行病理分析,包括CT和X光图像等。该模型使用了GPT-4、Vision Transformer和Vicuna语言模型进行训练,具备出色的多模态对话能力,并在生物医学数据集上取得了领先地位。
2025-04-20 09:51:52 -
![上海市发布AI与"元宇宙"关键技术攻关行动方案(2023-2025)]() 上海市发布AI与"元宇宙"关键技术攻关行动方案(2023-2025)
上海市发布AI与"元宇宙"关键技术攻关行动方案(2023-2025)本文介绍了上海市在2023年至2025年期间,关于"元宇宙"关键技术攻关的行动方案。主要以沉浸式技术和Web3技术为两大主攻方向,旨在加快推进"元宇宙"领域的科技自立自强,实现关键技术突破和产业化水平提升。
2025-04-20 09:26:28 -
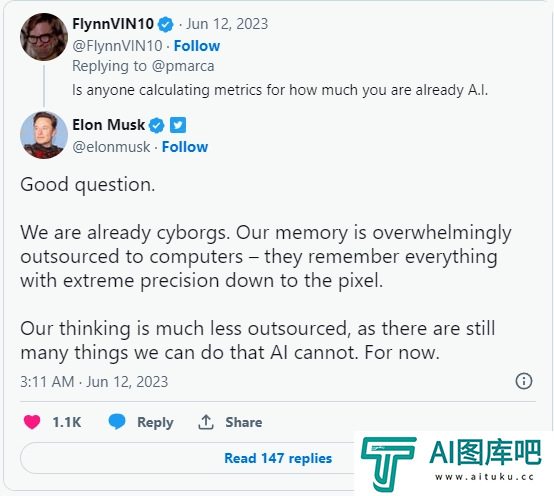
![马斯克:大量记忆存在电脑里,人类其实已经是“半机器生物”]() 马斯克:大量记忆存在电脑里,人类其实已经是“半机器生物”
马斯克:大量记忆存在电脑里,人类其实已经是“半机器生物”马斯克近日在推特上发表了他对人工智能时代当下的人类命运的看法。他认为,人类已经是半机器人,因为我们的记忆大部分都外包存储在电脑里。
2025-04-19 15:23:22 -
![AI换脸引发的风险隐患:马保国成网络热词,太不把混元形意掌门人放在眼里!]() AI换脸引发的风险隐患:马保国成网络热词,太不把混元形意掌门人放在眼里!
AI换脸引发的风险隐患:马保国成网络热词,太不把混元形意掌门人放在眼里!近日,马保国的脸成为网络热词,被人们使用AI换脸技术恶搞在各种人身上。这种行为背后反映出AI应用走偏所带来的风险隐患,引发了人们对肖像权和个人权益的严肃讨论。
2025-04-19 15:02:25 -
![东京都政府将全面引入生成式AI,推动创新施政效果]() 东京都政府将全面引入生成式AI,推动创新施政效果
东京都政府将全面引入生成式AI,推动创新施政效果东京都所有政府部门将于8月起引入以ChatGPT为代表的生成式AI。该举措旨在评估创新技术的积极和消极影响,并推动其在行政领域的应用,以实现更好的施政效果。
2025-04-19 14:40:09 -
![日本演艺界团体呼吁保护艺术从业者权益,要求对AI进行监管并建立“声音肖像权”]() 日本演艺界团体呼吁保护艺术从业者权益,要求对AI进行监管并建立“声音肖像权”
日本演艺界团体呼吁保护艺术从业者权益,要求对AI进行监管并建立“声音肖像权”日本演艺界团体,包括演员和音乐家在内的相关组织,向政府提交请愿书,要求披露使用AI生成内容的数据来源。他们呼吁政府审查版权法的运作,并制定规则以确立"声音肖像权",以保护艺术从业者的权益。
2025-04-19 14:19:30










-
![Music To Image音生图工具是什么_AI音频生成图像工具有哪些_AI音生图工具有哪些_Music To Image怎么用]() Music To Image音生图工具是什么_AI音频生成图像工具有哪些_AI音生图工具有哪些_Music To Image怎么用
Music To Image音生图工具是什么_AI音频生成图像工具有哪些_AI音生图工具有哪些_Music To Image怎么用「Music To Image」是一款AI音频生成图片的多模态转换工具,它的本质生成逻辑是音频→文本提示词→图像。
2024-12-17 00:06:33 -
![阿里旗下夸克APP上线“AI学习助手”:内置海量试题,拍照一键解疑,巧用大模型帮助当代学子高效备考、快速进阶]() 阿里旗下夸克APP上线“AI学习助手”:内置海量试题,拍照一键解疑,巧用大模型帮助当代学子高效备考、快速进阶
阿里旗下夸克APP上线“AI学习助手”:内置海量试题,拍照一键解疑,巧用大模型帮助当代学子高效备考、快速进阶夸克“AI学习助手”采用夸克宝宝的虚拟形象为用户进行题目讲解。基于大语言模型和视觉技术,AI智能讲解能够给用户提供 “考点分析”、“详解步骤”、“答案总结”等详细内容。
2025-02-18 16:08:16 -
![阿里寻光_寻光视频创作平台_寻光视频创作官方网站]() 阿里寻光_寻光视频创作平台_寻光视频创作官方网站
阿里寻光_寻光视频创作平台_寻光视频创作官方网站AIGC时代,视频创作这事儿真的不一样了。就像这样,轻轻一圈,选定目标立刻变身单独图层,再丝滑嵌入不同的背景视频,场景变换so easy~
2025-01-16 11:04:19 -
![AI动漫视频生成_yoyo官方网站_yoyo功能及介绍]() AI动漫视频生成_yoyo官方网站_yoyo功能及介绍
AI动漫视频生成_yoyo官方网站_yoyo功能及介绍视频生成赛道又起新秀,而且还是二次元定制版!稳定产出电影级画面,一键文 图生成视频,即使是「手残党」也能复刻自己喜欢的动漫作品了。
2025-01-16 11:53:08 -
![AI写真生成器妙鸭相机免费体验版实测_仅需8张自拍]() AI写真生成器妙鸭相机免费体验版实测_仅需8张自拍
AI写真生成器妙鸭相机免费体验版实测_仅需8张自拍在小红书、朋友圈刷屏的“妙鸭相机”,还记得吗?9月20日,这家AI快消应用公司宣布“妙鸭相机”免费体验版本正式上线啦!本次更新的“妙鸭相机”APP,专业版要求上传的图片数量也从20张下调到15张了哟
2024-12-16 09:21:10 -
![网易出品的免费AI在线绘画工具:AI绘画工坊,安利给大家]() 网易出品的免费AI在线绘画工具:AI绘画工坊,安利给大家
网易出品的免费AI在线绘画工具:AI绘画工坊,安利给大家网易出品推出的云端Stable Diffusion简直太好用了,集成了多种模型任你选,想生成什么类型的图像都超级容易。
2024-12-16 09:26:04 -
AI绘画ComfyUI进阶教程丨插件IPAdapter的详细使用教程,风格模仿,换脸全靠它
哈咯大家好,本期正式给大家带来进阶部分的插件讲解教程,虽然很多朋友一直在用IPA但可能很多朋友还不太了解其结构,希望这期关于ipa用法的教程能对大家有所帮助吧!
2024-12-17 22:49:30 -
![阿里云通义千问上线AIGC春节新玩法:AI帮你免费拍摄全家福,AI舞蹈视频生成器“全民舞王”新增春晚舞蹈]() 阿里云通义千问上线AIGC春节新玩法:AI帮你免费拍摄全家福,AI舞蹈视频生成器“全民舞王”新增春晚舞蹈
阿里云通义千问上线AIGC春节新玩法:AI帮你免费拍摄全家福,AI舞蹈视频生成器“全民舞王”新增春晚舞蹈春节将至年味渐浓,阿里云通义千问APP上线多项免费新应用,涵盖全家福、拜新年、万物成龙等图像生成的新玩法。
2025-02-13 15:39:26 -
![有手就行:Stability AI推出简笔画生成图片工具Stable Doodle]() 有手就行:Stability AI推出简笔画生成图片工具Stable Doodle
有手就行:Stability AI推出简笔画生成图片工具Stable Doodle近日,图像生成模型 Stable Diffusion 背后的初创公司 Stability AI 推出了一项新的服务,可以将简笔画转换为图像。这项服务名为 Stable Doodle,利用最新的 Stable Diffusion 模型分析简笔画的轮廓,让每个人都能得到堪称艺术的作品。
2025-04-10 13:09:46 -
![应用商店下载排行第一,“Meta版推特”Threads注册用户超5000万]() 应用商店下载排行第一,“Meta版推特”Threads注册用户超5000万
应用商店下载排行第一,“Meta版推特”Threads注册用户超5000万新上线社交应用Threads已注册激活用户超过5000万,该数字仍在持续增长。当前在英国和美国苹果应用商店免费应用中的下载量排名第一。
2025-04-14 13:36:13