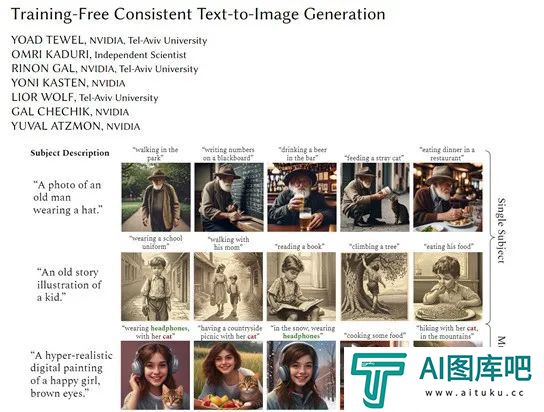
英伟达推出免训练,可生成连贯图片的文生图模型ConsiStory
目前,多数文生图模型皆使用的是随机采样模式,使得每次生成的图像效果皆不同,在生成连贯的图像方面非常差。
例如,想通过AI生成一套图像连环画,即便使用同类的提示词也很难实现。虽然DALL·E 3和Midjourney可以对图像实现连贯的生成控制,但这两个产品都是闭源的。
因此,英伟达和特拉维夫大学的研究人员开发了免训练一致性连贯文生图模型——ConsiStory。(即将开源)
论文地址:https://arxiv.org/abs/2402.03286
目前,文生图模型在生成内容一致性方面比较差的原因主要有两个:1)无法识别和定位图像中的共同主体,文生图像模型没有内置的对象检测或分割模块,很难自动识别不同图像中的相同主体;
2)无法在不同图像中保持主体的视觉一致性,即使定位到主体,也很难使不同步骤中独立生成的主体在细节上保持高度相似。
主流解决这两种难题的方法是,基于个性化和编码器的优化方法。但这两类方法都需要额外的训练流程,例如,针对特定主体微调模型参数,或使用目标图像训练编码器作为条件。
即便使用了这种优化方法,训练周期较长难以扩展到多个主体,且容易与原始模型分布偏离。
而ConsiStory提出了一种全新的方法,通过共享和调整模型内部表示,可以在无需任何训练或调优的情况下实现主体的一致性。
值得一提的是,ConsiStory可以作为一种插件,帮助其他扩散模型提升文生图的一致性和连贯性。
主体驱动自注意力(SDSA)
SDSA是ConsiStory的核心模块之一,可以在生成的图像批次**享主体相关的视觉信息,使不同图像中的主体保持一致的外观。
SDSA主要扩大了扩散模型中自注意力层,允许一个图像中的“提示词”不仅可以关注自己图像的输出结果,还可以关注批次中其他图像的主体区域的输出结果。
这样主体的视觉特征就可以在整个批次**享,不同图像中的主体互相"对齐"。
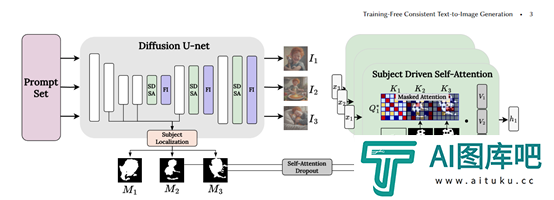
为了防止背景区域之间的敏感信息泄露,该模块使用主体分割蒙版来进行遮蔽——每个图像只能关注批次中其他图像主体区域的输出结果。

主体蒙版是通过扩散模型本身的交叉注意力特征自动提取。
特征注入
为了进一步增强主体不同图像之间细节层面的一致性,“特征注入”基于扩散特征空间建立的密集对应图,可以在图像之间共享自注意力输出特征。
同时图像中一些相似的优化地方之间共享自注意力特征,这可以有效确保主体相关的纹理、颜色等细节特征在整个批次中互相"对齐"。
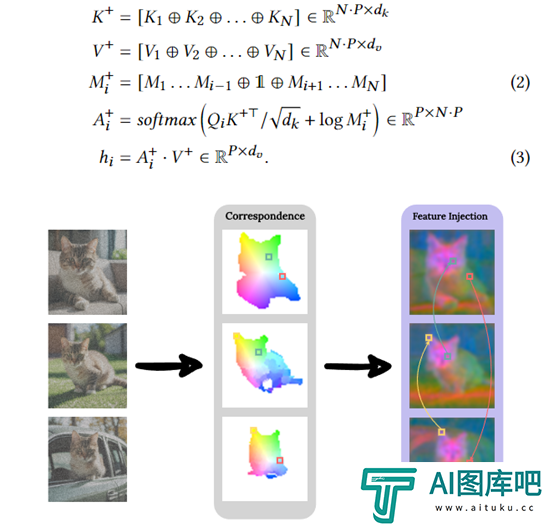
特征注入也使用主体蒙版进行遮蔽,只在主体区域执行特征共享。同时还设置相似度阈值,只在足够相似的优化之间执行。
锚图像和可重用主体
ConsiStory中的锚图像提供了主题信息的参考功能,主要用于引导图像生成过程,确保生成的图像在主题上保持一致。
锚图像可以是用户提供的图像,也可以是从其他来源获取的相关图像。在生成过程中,模型会参考锚图像的特征和结构,并尽可能地生成与一致性的图像。

可重用主体是通过共享预训练模型的内部激活,来实现主题一致性的方法。在图像生成过程中,模型会利用预训练模型的内部特征表示来对生成的图像进行对齐,而无需进一步对齐外部来源的图像。

也就是说生成的图像可以相互关注、共享特征,这使得ConsiStory实现了0训练成本,避免了传统方法中需要针对每个主题进行训练的难题。
-
![英伟达推出免训练,可生成连贯图片的文生图模型ConsiStory]() 英伟达推出免训练,可生成连贯图片的文生图模型ConsiStory
英伟达推出免训练,可生成连贯图片的文生图模型ConsiStory目前,多数文生图模型皆使用的是随机采样模式,使得每次生成的图像效果皆不同,在生成连贯的图像方面非常差。英伟达和特拉维夫大学的研究人员开发了免训练一致性连贯文生图模型——ConsiStory。(即将开源
2025-02-12 16:35:34 -
![sora生成视频出现错误_马斯克激辩世界模型]() sora生成视频出现错误_马斯克激辩世界模型
sora生成视频出现错误_马斯克激辩世界模型现实不存在了?这么说还为时尚早。最近,Sora各种不符合现实的图出圈了,惹网友爆笑。LeCun、DeepMind大佬、马斯克都纷纷下场了,而一位动画师表示,自己完全不担心被Sora淘汰。
2025-02-12 16:09:34 -
![OpenAI开通抖音TikTok官号:狂发Sora视频真假难辨!短视频大V惨叫:我准备退网了]() OpenAI开通抖音TikTok官号:狂发Sora视频真假难辨!短视频大V惨叫:我准备退网了
OpenAI开通抖音TikTok官号:狂发Sora视频真假难辨!短视频大V惨叫:我准备退网了Sora的新视频,现在成了抖音独占!OpenAI正式开通了国际版抖音TikTok的官方账号。接连发布了几条短视频,配上洗脑BGM让人刷得停不下来。
2025-02-12 15:48:02 -
![微软证实:Sora视频模型将会被整合入Copilot,但时间表不明确]() 微软证实:Sora视频模型将会被整合入Copilot,但时间表不明确
微软证实:Sora视频模型将会被整合入Copilot,但时间表不明确近日,微软证实OpenAI的Sora最终将与Copilot集成,但是整合的具体时间表尚不清楚。微软方面给出了肯定的答复:“最终会落地,但这需要时间。”
2025-02-12 15:21:41 -
![为何是OpenAI,而不是别人搞出了Sora?一线员工作息时间揭秘研发历程:996疯狂卷了一年]() 为何是OpenAI,而不是别人搞出了Sora?一线员工作息时间揭秘研发历程:996疯狂卷了一年
为何是OpenAI,而不是别人搞出了Sora?一线员工作息时间揭秘研发历程:996疯狂卷了一年OpenAI采取的商业模式以及其对于AGI的信奉、系统性的方法论以及积极的尝试,都在推动他们朝着目标前进,是其能够在众多研究机构和公司中脱颖而出的重要因素。
2025-02-12 14:59:16 -
![谷歌发布最强开源“小模型”Gemma丨ChatGPT再次出现大范围“胡言乱语”丨AI芯片发力,英伟达Q4财报喜人]() 谷歌发布最强开源“小模型”Gemma丨ChatGPT再次出现大范围“胡言乱语”丨AI芯片发力,英伟达Q4财报喜人
谷歌发布最强开源“小模型”Gemma丨ChatGPT再次出现大范围“胡言乱语”丨AI芯片发力,英伟达Q4财报喜人【AI奇点网2024年2月22日早报】本站每日播报AI业界最新资讯,触摸时代脉搏,掌握未来科技动向。事不宜迟,点击查看今日AI资讯早餐。
2025-02-12 14:34:26










-
![如何使用 ChatGPT 调试代码]() 如何使用 ChatGPT 调试代码
如何使用 ChatGPT 调试代码当您的代码出现问题时,您可以向 ChatGPT 提供故障代码和问题描述。AI 工具将尝试识别并纠正问题。
2024-12-31 12:01:41 -
思维脑图工具也能创作AI绘画作品,如何使用博思白板进行AI绘画
博思白板boardmix的创作平台提供多种登录方式,最方便要属直接微信扫码登录,然后绑定手机号实名制。再点击页面正中央紫色的按钮「免费使用」,你就可以进入博思白板boardmix的内容创作操作台。
2024-12-26 09:08:34 -
![AI绘图模型测评_Meta Imagine发布_Meta Imagine最新地址]() AI绘图模型测评_Meta Imagine发布_Meta Imagine最新地址
AI绘图模型测评_Meta Imagine发布_Meta Imagine最新地址针对Meta Imagine,Midjourney,Adobe Firefly,Dalle,这四个我心目中的比较大的AI绘图模型测评。我会从细节质量、审美(构图色彩等)、风格多样化、语义理解这四个维度来评测,每个维度3个Prompt,同时每个Prompt我会在AI绘图模型中roll3次,取效果最具有代表性的那个图,尽量减少偏见。
2024-12-13 17:44:01 -
![快手AI文生视频大模型【可灵】首发实测:这可能将成为真正意义的第一款「中国版Sora」]() 快手AI文生视频大模型【可灵】首发实测:这可能将成为真正意义的第一款「中国版Sora」
快手AI文生视频大模型【可灵】首发实测:这可能将成为真正意义的第一款「中国版Sora」昨天,6月6号,是快手的13周年生日。在这一天,所有AI圈的人都想不到,快手在13周年之际,没有任何预兆、没有任何宣传,直接发布了他们的AI视频大模型。可灵。
2024-12-13 20:45:55 -
Stable Diffusion 3最新模型测评丨SD3模型ComfyUI流程简单搭建
由于前不久StabilityAI开放了SD3新模型的使用权,这期我们就简单聊聊这款新模型的使用方法,以及StabilityAI对于SD3模型的发布策略,和未来的发展预期!如果本期讯息对大家有所帮助,就点赞关注支持欧阳一下吧!
2024-12-13 21:10:24 -
![科大讯飞星火大模型3.0实测:高能进化,给AI注入灵魂,部分能力与GPT-4旗鼓相当]() 科大讯飞星火大模型3.0实测:高能进化,给AI注入灵魂,部分能力与GPT-4旗鼓相当
科大讯飞星火大模型3.0实测:高能进化,给AI注入灵魂,部分能力与GPT-4旗鼓相当科大讯飞星火认知大模型3 0正式发布。星火3 0的整体性能已经超越ChatGPT,部分能力与GPT-4旗鼓相当。科大讯飞立下又一个Flag,星火4 0要对标GPT-4
2024-12-13 22:43:43 -
高考大模型测评_豆包文科成绩领先
什么?好多大模型的文科成绩超一本线,还是最卷的河南省???没错,最近就有这么一项大模型“高考大摸底”评测走红了。河南高考文科今年的一本线是521分,根据这项评测,共计四个大模型大于或等于这个分数,其中头两名最值得关注:
2024-12-13 23:27:45 -
![ChatGPT、阿里通义等AI机器人参加今年高考出分:干翻90%考生,有一科全员不及格]() ChatGPT、阿里通义等AI机器人参加今年高考出分:干翻90%考生,有一科全员不及格
ChatGPT、阿里通义等AI机器人参加今年高考出分:干翻90%考生,有一科全员不及格6月19日,上海人工智能实验室和司南评测体系发布了国内首个针对AI大模型参与2024高考「语数英」三科目的全卷解题能力测试的结果。
2024-12-13 23:42:30 -
![深度解析丨ControlNet模型的工作原理与应用场景(附案例解析)]() 深度解析丨ControlNet模型的工作原理与应用场景(附案例解析)
深度解析丨ControlNet模型的工作原理与应用场景(附案例解析)大家好,我是言川。本期文章是2024年的第一篇文章,也是2023年农历的最后一篇文章。截至这篇文章完成时,距离春节也只有最后一周的时间了,我无法单独向支持我的朋友们传达祝福之意。所以在本篇文章的开头,向大家说一些祝福之词
2024-12-18 09:12:30 -
AI绘画进阶入门ComfyUI系列教程丨第八章,只需一步极速出图,实时绘画!!
这期继续为大家分享comfyUI的相关知识LCM和Turbo的极速出图方法,希望对大家有所帮助!
2024-12-18 10:37:06