Stable Diffusion 3技术报告公开:基于Sora生成构架,开源图像模型有望超越Midjourney、DALL·E等闭源模型
当地时间3月5日,Stability AI在发布了Stable Diffusion 3之后,公布了详细的技术报告。论文深入分析了Stable Diffusion 3的核心技术——改进版的Diffusion模型和一个基于DiT的文生图全新架构!

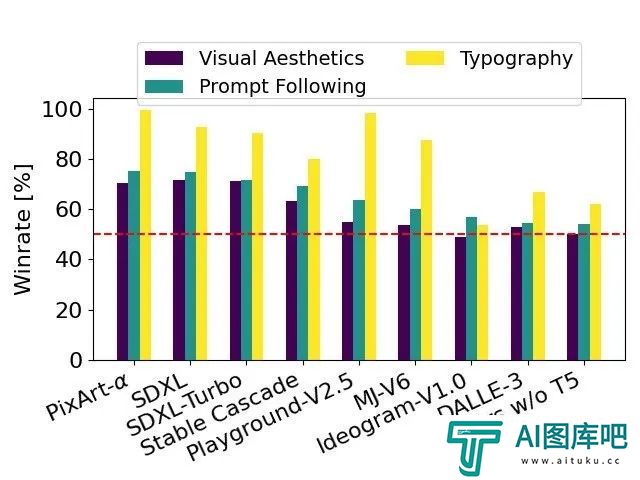
通过人类评价测试,Stable Diffusion 3在字体设计和对提示的精准响应方面,超过了DALL·E 3、Midjourney v6和Ideogram v1.
Stability AI新开发的多模态扩散Transformer(MMDiT)架构,采用了分别针对图像和语言表示的独立权重集,与SD 3的早期版本相比,显著提升了对文本的理解和文字的拼写能力。

性能评估
在人类反馈的基础之上,技术报告将Stable Diffusion3于大量开源模型SDXL、SDXL Turbo、Stable Cascade、Playground v2.5 和 Pixart-α,以及闭源模型DALL·E 3、Midjourney v6 和 Ideogram v1进行了详细的对比评估。
评估员根据与给定提示的一致性、文本的清晰度以及图像的整体美观度选择了每个模型的最佳输出:

测试结果显示,无论是在遵循提示的准确性、文本的清晰呈现还是图像的视觉美感方面,Stable Diffusion 3都达到或超过了当前文生图生成技术的最高水平。
完全没有针对硬件进行过优化的SD 3模型具有8B参数,能够在24GB显存的RTX 4090消费级GPU上运行,并且在使用50个采样步骤的情况下,生成1024x1024分辨率的图像需耗时34秒。
此外,Stable Diffusion 3在发布时将提供多个版本,参数范围从8亿到80亿,从而能以进一步降低使用的硬件门槛。

生图架构细节曝光
在文生图的过程中,模型需同时处理文本和图像这两种不同的信息。所以作者将这个新框架称之为MMDiT。
在文本到图像生成的过程中,模型需同时处理文本和图像这两种不同的信息类型。这就是作者将这种新技术称为MMDiT(多模态Diffusion Transformer的简称)的原因。
与Stable Diffusion之前的版本一样,Stable Diffusion3采用了预训练模型来提取适合的文本和图像的表达形式。
具体而言,他们利用了三种不同的文本编码器——两个CLIP模型和一个T5 ——来处理文本信息,同时使用了一个更为先进的自编码模型来处理图像信息。
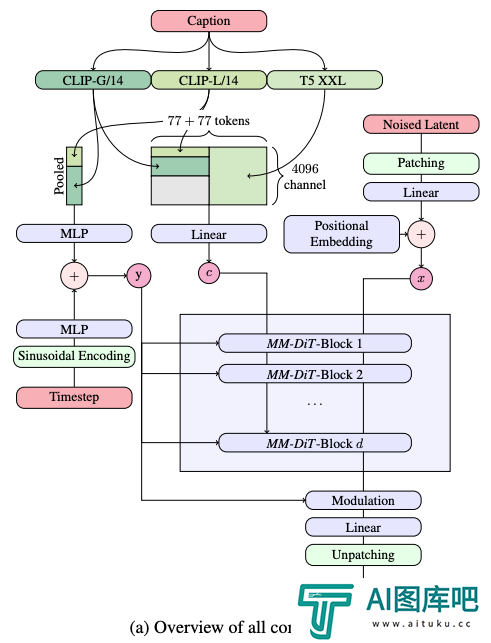
Stable Diffusion3的架构是在Diffusion Transformer(DiT)的基础上建立的。由于文本和图像信息的差异,SD 3为这两种信息各自设置了独立的权重。
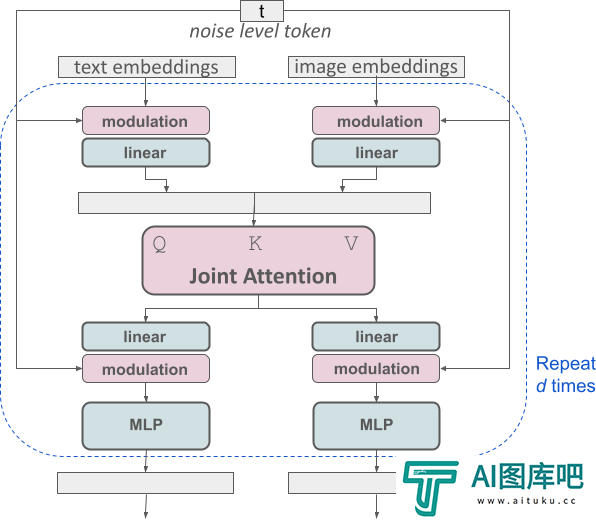
这种设计相当于为每种信息类型配备了两个独立的Transformer,但在执行注意力机制时,会将两种信息的数据序列合并,这样就可以在各自的领域内独立工作的同时,能保持够相互参考和融合。
通过这种独特的构架,图像和文本信息之间可以相互流动和交互,从而在生成的结果中提高对内容的整体理解和视觉表现。
而且,这种架构未来还可以轻松扩展到其他包括视频在内的多种模态。

得益于SD 3在遵循提示方面的进步,模型能够精确生成集中于多种不同主题和特性的图像,同时在图像风格上也保持了极高的灵活性。

通过重赋权法改进Rectified Flow
除了推出的全新Diffusion Transformer构架之外,SD 3对于Diffusion模型也进行了重大的改进。
SD 3采用了Rectified Flow(RF)策略,将训练数据和噪声沿着直线轨迹连接起来。
这种方法让模型的推理路径更加直接,因此可以通过更少的步骤完成样本的生成。
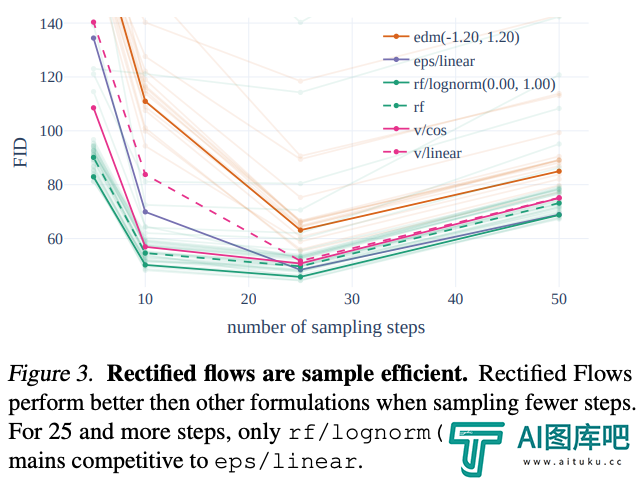
作者在训练流程中引入了一种创新的轨迹采样计划,特别增加了对轨迹中间部分的权重,这些部分的预测任务更具挑战性。
通过与其他60种扩散轨迹(例如 LDM、EDM 和 ADM)进行比较,作者发现尽管之前的RF方法在少步骤采样中表现更佳,但随着采样步骤增多,性能会慢慢下降。
为了避免这种情况的出现,作者提出的加权RF方法,就能够持续提升模型性能。
扩展RF Transformer模型
Stability AI训练了多个不同规模的模型,从 15 个模块、450M参数到38个模块、8B参数,发现模型大小和训练步骤都能平滑地降低验证损失。
为了验证这是否意味着模型输出有实质性的改进,他们还评估了自动图像对齐指标和人类偏好评分。
结果表明,这些评估指标与验证损失强相关,说明验证损失是衡量模型整体性能的有效指标。
此外,这种扩展趋势没有达到饱和点,让我们对未来能够进一步提升模型性能持乐观态度。
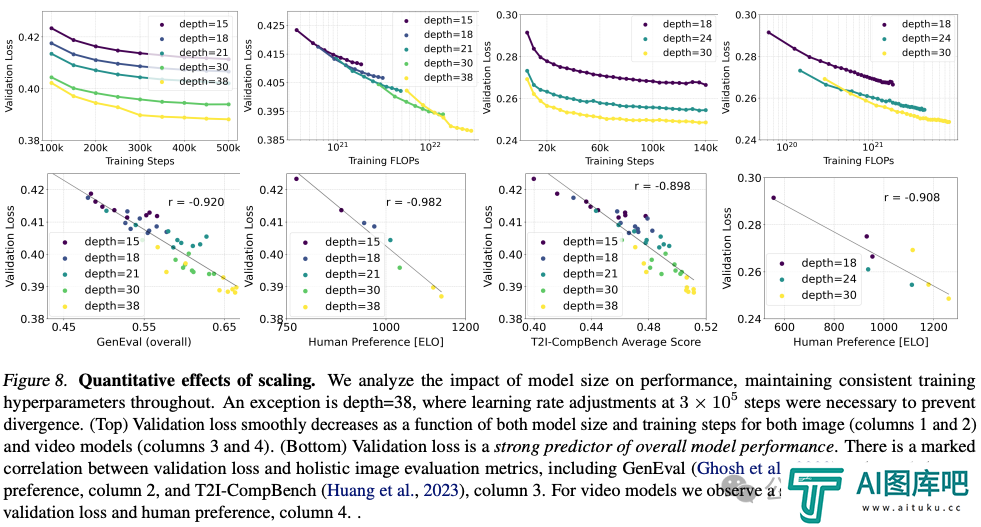
作者在256 *256像素分辨率下,在4096的批大小下,用不同参数数对模型进行了500k步训练。

上图说明了长时间训练较大模型对样本质量的影响。
上表显示了GenEval的结果。当使用作者提出的训练方法并提高训练图像的分辨率时,最大的模型在大多数类别中都表现出色,在总分上超过了 DALL·E 3。
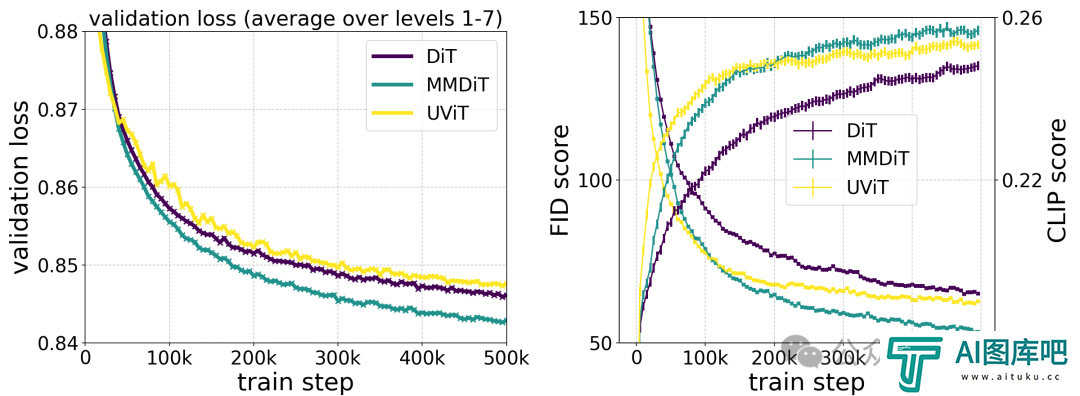
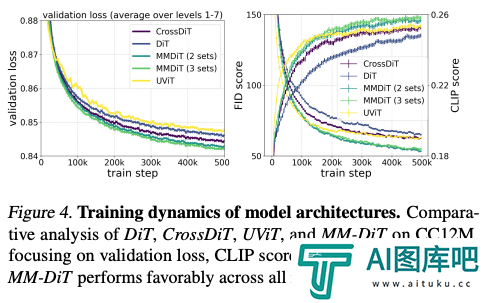
根据作者对不同构架模型的测试对比,MMDiT效果非常好,超过了DiT,Cross DiT,UViT,MM-DiT。
灵活的文字文本编码器
通过在推理阶段去除占用大量内存的4.7B参数的T5文本编码器,Stable Diffusion 3的内存需求得到了大幅降低,而性能损失微乎其微。
去除这个文本编码器不会影响图像的视觉美感(不使用T5的胜率为 50%),只会略微降低文本的准确遵循能力(胜率为46%)。
然而,为了充分发挥Stable Diffusion3在生成文字的能力,作者还是建议使用T5编码器。
因为作者发现在没有它的情况下,排版生成文字的性能会有更大的下降(胜率为 38%)。

-
![Stable Diffusion 3技术报告公开:基于Sora生成构架,开源图像模型有望超越Midjourney、DALL·E等闭源模型]() Stable Diffusion 3技术报告公开:基于Sora生成构架,开源图像模型有望超越Midjourney、DALL·E等闭源模型
Stable Diffusion 3技术报告公开:基于Sora生成构架,开源图像模型有望超越Midjourney、DALL·E等闭源模型Stability AI在发布了Stable Diffusion 3之后,公布了详细的技术报告。核心技术——改进版的Diffusion模型和一个基于DiT的文生图全新架构!
2025-02-11 09:45:47 -
![马斯克与奥特曼「八年的爱恨情仇」:从兄弟联手创办OpenAI,到理念不合、分道扬镳、相爱相杀、对薄公堂]() 马斯克与奥特曼「八年的爱恨情仇」:从兄弟联手创办OpenAI,到理念不合、分道扬镳、相爱相杀、对薄公堂
马斯克与奥特曼「八年的爱恨情仇」:从兄弟联手创办OpenAI,到理念不合、分道扬镳、相爱相杀、对薄公堂马斯克与OpenAI、Altman之间,还有一些从未公开的秘密。他们之间究竟经历了什么?华尔街日报一篇长文,讲述了马斯克与Altman的「兄弟情谊」如何走向终结。
2025-02-11 09:18:12 -
![OpenAI完成奥特曼被罢免内部调查丨Midjourney将Stability AI拉黑丨马斯克:OpenAI更名CloseAI就撤诉]() OpenAI完成奥特曼被罢免内部调查丨Midjourney将Stability AI拉黑丨马斯克:OpenAI更名CloseAI就撤诉
OpenAI完成奥特曼被罢免内部调查丨Midjourney将Stability AI拉黑丨马斯克:OpenAI更名CloseAI就撤诉【AI奇点网2024年3月8日早报】本站每日播报AI业界最新资讯,触摸时代脉搏,掌握未来科技动向。事不宜迟,点击查看今日AI资讯早餐。
2025-02-10 17:50:43 -
二月AI爆炸!除了SORA你还知道哪个AI工具?
二月份以来出了很多AI工具,除了sora,stability AI,stable video,还有很多大模型的新技术!
2025-02-10 17:27:24 -
![AI视频又炸了!照片+声音变视频,阿里emo让Sora女主唱歌小李子说rap]() AI视频又炸了!照片+声音变视频,阿里emo让Sora女主唱歌小李子说rap
AI视频又炸了!照片+声音变视频,阿里emo让Sora女主唱歌小李子说rapSora之后,居然还有新的AI视频模型,能惊艳得大家狂转狂赞!这就是阿里最新推出的基于音频驱动的肖像视频生成框架,EMO(Emote Portrait Alive)。
2025-02-10 16:57:29 -
![李彦宏:文心大模型推理成本降低到初始版本的1%,生成式AI重构所有ToC产品]() 李彦宏:文心大模型推理成本降低到初始版本的1%,生成式AI重构所有ToC产品
李彦宏:文心大模型推理成本降低到初始版本的1%,生成式AI重构所有ToC产品2月28日,百度发布2023年第四季度及全年财报。据预计,今年百度来自生成式AI和基础模型的增量收入将达到数十亿元。
2025-02-10 16:30:12









-
![如何使用 ChatGPT 调试代码]() 如何使用 ChatGPT 调试代码
如何使用 ChatGPT 调试代码当您的代码出现问题时,您可以向 ChatGPT 提供故障代码和问题描述。AI 工具将尝试识别并纠正问题。
2024-12-31 12:01:41 -
思维脑图工具也能创作AI绘画作品,如何使用博思白板进行AI绘画
博思白板boardmix的创作平台提供多种登录方式,最方便要属直接微信扫码登录,然后绑定手机号实名制。再点击页面正中央紫色的按钮「免费使用」,你就可以进入博思白板boardmix的内容创作操作台。
2024-12-26 09:08:34 -
![AI绘图模型测评_Meta Imagine发布_Meta Imagine最新地址]() AI绘图模型测评_Meta Imagine发布_Meta Imagine最新地址
AI绘图模型测评_Meta Imagine发布_Meta Imagine最新地址针对Meta Imagine,Midjourney,Adobe Firefly,Dalle,这四个我心目中的比较大的AI绘图模型测评。我会从细节质量、审美(构图色彩等)、风格多样化、语义理解这四个维度来评测,每个维度3个Prompt,同时每个Prompt我会在AI绘图模型中roll3次,取效果最具有代表性的那个图,尽量减少偏见。
2024-12-13 17:44:01 -
![快手AI文生视频大模型【可灵】首发实测:这可能将成为真正意义的第一款「中国版Sora」]() 快手AI文生视频大模型【可灵】首发实测:这可能将成为真正意义的第一款「中国版Sora」
快手AI文生视频大模型【可灵】首发实测:这可能将成为真正意义的第一款「中国版Sora」昨天,6月6号,是快手的13周年生日。在这一天,所有AI圈的人都想不到,快手在13周年之际,没有任何预兆、没有任何宣传,直接发布了他们的AI视频大模型。可灵。
2024-12-13 20:45:55 -
Stable Diffusion 3最新模型测评丨SD3模型ComfyUI流程简单搭建
由于前不久StabilityAI开放了SD3新模型的使用权,这期我们就简单聊聊这款新模型的使用方法,以及StabilityAI对于SD3模型的发布策略,和未来的发展预期!如果本期讯息对大家有所帮助,就点赞关注支持欧阳一下吧!
2024-12-13 21:10:24 -
![科大讯飞星火大模型3.0实测:高能进化,给AI注入灵魂,部分能力与GPT-4旗鼓相当]() 科大讯飞星火大模型3.0实测:高能进化,给AI注入灵魂,部分能力与GPT-4旗鼓相当
科大讯飞星火大模型3.0实测:高能进化,给AI注入灵魂,部分能力与GPT-4旗鼓相当科大讯飞星火认知大模型3 0正式发布。星火3 0的整体性能已经超越ChatGPT,部分能力与GPT-4旗鼓相当。科大讯飞立下又一个Flag,星火4 0要对标GPT-4
2024-12-13 22:43:43 -
高考大模型测评_豆包文科成绩领先
什么?好多大模型的文科成绩超一本线,还是最卷的河南省???没错,最近就有这么一项大模型“高考大摸底”评测走红了。河南高考文科今年的一本线是521分,根据这项评测,共计四个大模型大于或等于这个分数,其中头两名最值得关注:
2024-12-13 23:27:45 -
![ChatGPT、阿里通义等AI机器人参加今年高考出分:干翻90%考生,有一科全员不及格]() ChatGPT、阿里通义等AI机器人参加今年高考出分:干翻90%考生,有一科全员不及格
ChatGPT、阿里通义等AI机器人参加今年高考出分:干翻90%考生,有一科全员不及格6月19日,上海人工智能实验室和司南评测体系发布了国内首个针对AI大模型参与2024高考「语数英」三科目的全卷解题能力测试的结果。
2024-12-13 23:42:30 -
![深度解析丨ControlNet模型的工作原理与应用场景(附案例解析)]() 深度解析丨ControlNet模型的工作原理与应用场景(附案例解析)
深度解析丨ControlNet模型的工作原理与应用场景(附案例解析)大家好,我是言川。本期文章是2024年的第一篇文章,也是2023年农历的最后一篇文章。截至这篇文章完成时,距离春节也只有最后一周的时间了,我无法单独向支持我的朋友们传达祝福之意。所以在本篇文章的开头,向大家说一些祝福之词
2024-12-18 09:12:30 -
AI绘画进阶入门ComfyUI系列教程丨第八章,只需一步极速出图,实时绘画!!
这期继续为大家分享comfyUI的相关知识LCM和Turbo的极速出图方法,希望对大家有所帮助!
2024-12-18 10:37:06