中文语音克隆BertVits2_开源TTS项目有哪些
曾经我写过一篇做语音克隆的AI音频工具:11Labs
效果好是好,也非常傻瓜简单,但是很多朋友都跟我反馈说,11Labs中文效果不好。
没办法,毕竟国外的产品,在世界的AI产品舞台上,中文从来不是主流语言。这也是一个非常让人伤心的话题,明明世界AI圈里,主流的从业人员都是华人,但是中文的数据集和效果...哎。
而国内的AI音频产品,比如出门问问的魔音工坊,效果确实很好,而且他们也有做媲美11Labs语音克隆的实力,但是因为国内很多很多的原因,内部做出来了,有时候也不太对外放出来...具体的原因我就不细聊了,反正,懂得都懂。
总之,还是得靠自己,所以去年我12月翻了很久的TTS项目之后,找到了这个:
Bert-Vits-2
但是吧,这个效果虽好,但是没有好的特别影响代差的地步,直到上周有个大佬传了一个分支项目:
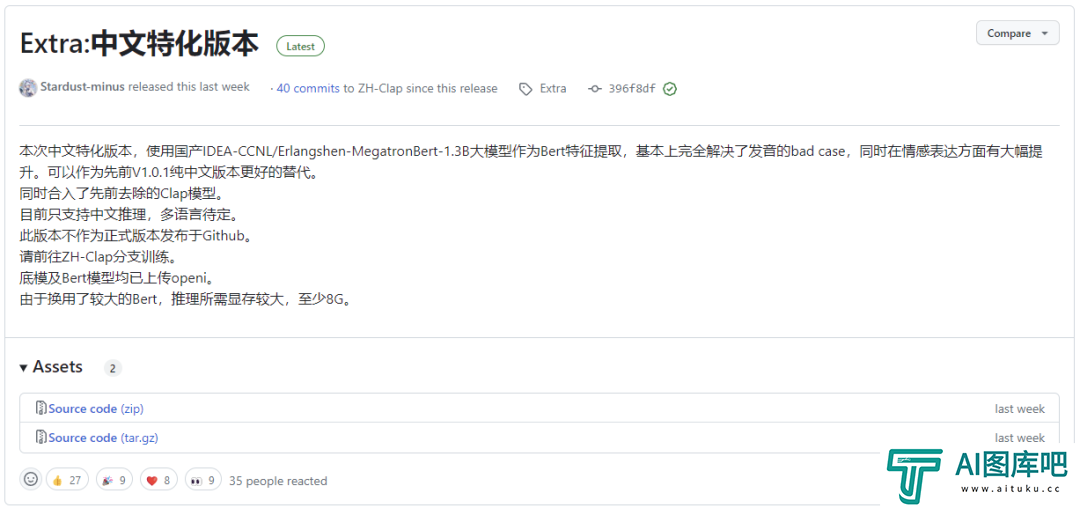
我觉得,中文语音克隆TTS的最强项目,到来了。
可以听听看,我去网上扒了B站UP主“峰哥亡命天涯”的音频,训练成TTS模型之后,说话的效果:
AI峰哥说话demo,数字生命卡兹克,22秒
这可能是目前市面上,开源TTS这块,我能体验到的最好的中文音频克隆效果了。
话不多说,开始教程,这次不是那么傻瓜,会有一点点麻烦,需要点好多下,但是毕竟各种乱七八糟的坑我都基本踩了个遍,所以我尽量写的清晰明白,让大家都能最方便快捷的训练自己的中文TTS。
首先,第一步,肯定是上云,云会让大家成功率最高,少踩一些坑,也花不了几块钱;
打开我们的国际标准炼丹平台AutoDL:https://www.autodl.com/
没注册的自己去链接注册去,我就不管了。
然后在西北A区租一台4090的机器。
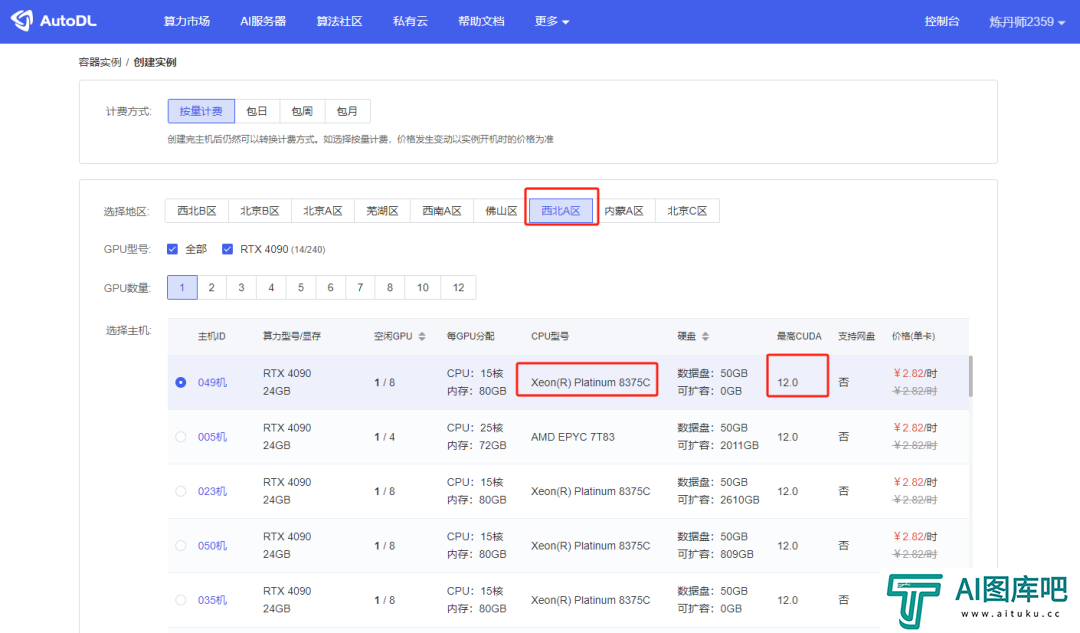
这里要注意一下,CPU型号别选AMD的,右边有一列叫“最高CUDA”,一定要大于11.8的,西北A区的一般都是12.0所以没啥问题,但是还是要留心一下,CUDA版本小于11.8必报错。
然后在下方,选择社区镜像,就是别人已经做好的系统我们直接拿来用就行了。在输入框中输入Bert-Vits,就会自动联想出来一堆,一定!一定!一定要选V11.1版本!!!要不然必报错!!!
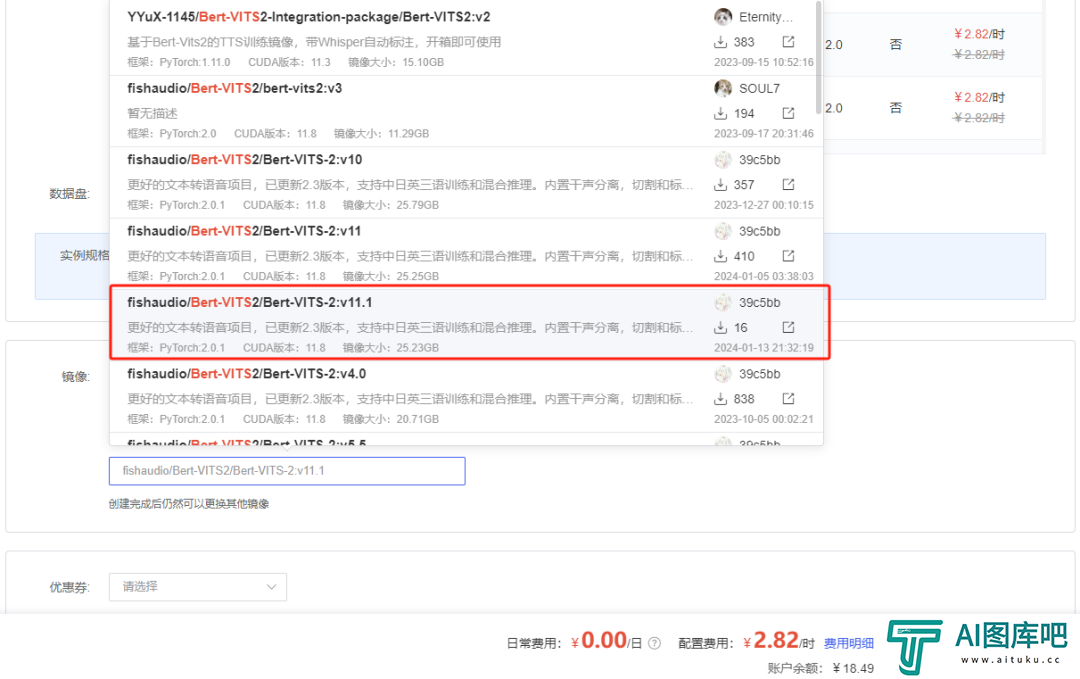
选完之后,我们就可以点击创建镜像。
第一次创建镜像,可能会非常久,大概需要将近10分钟,不要急,耐心等等就好。
创建完成之后,点击JupyterLab进入系统。
进来后就会看到一大堆文字,不用管,直接往下滑,直到看到分割线页面,点击第一个代码块,然后点上方的三角按钮运行这个代码块。
同时注意一下右上角这个圆圈的状态。
实心圆则代表系统正在运行中,空心圆则代表上一步已经运行完成,目前系统空闲中。
所以只有当看到右上角圆圈是空心圆的时候,再去运行下面的代码块。
第二个代码块比较重要,你可以先把这句话的speaker="Neuro" ,后面的这个Neuro改成你自己的名字,比如我就改成了speaker="Khazix"
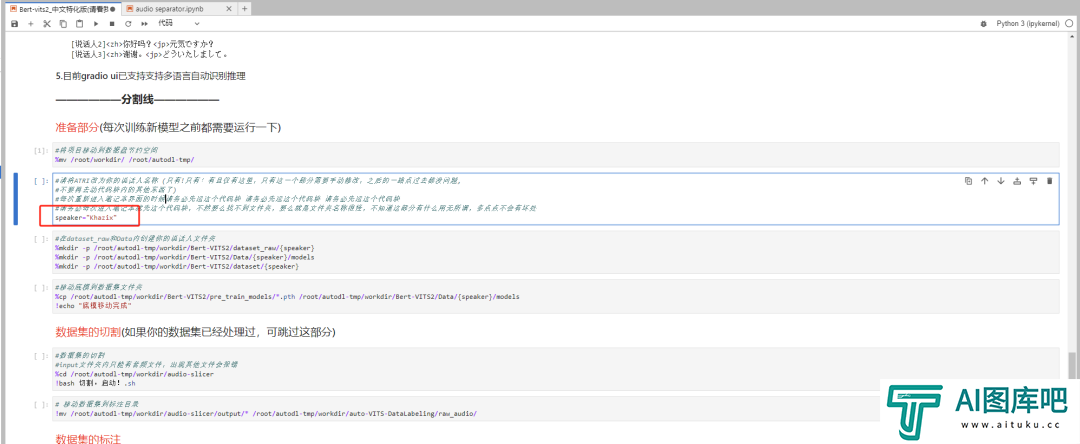
改完以后,再点顶上的三角按钮运行。
后续的两个代码块,都不需要运行任何东西,跟着运行即可。但是记得右上角的圆圈状态一定要是空心圆再运行!

这四步都运行完了之后,接下来就是数据集的上传与切割,我们大概需要半个小时到1个小时的纯人声说话的干声,一定要干声!尽量不要有任何杂音,这样效果才好。
同时注意你的口吻,最好是比较日常的、说话的,不要唱歌的、不要念课文的,要不然出来的效果也是稀奇古怪的朗读腔。
TTS大模型这种东西,90%的效果其实都跟原始数据集有密切的关系。
数据集这块,我们一般都是需要处理成多段10~15秒的音频的,如果你没有切割过的话,你可以直接把你的文件传到autodl-tmp/workdir/audio-slicer/input这个文件夹里,然后自己直接在代码块点击后运行即可。
如果你是已经在本地用slicer-gui切过的同学,你就可以直接把数据集上传到autodl-tmp/workdir/auto-VITS-DataLabeling/raw_audio这个路径下,直接拖进来就行。
就像这样,注意一下下面的蓝色的进度条就行,没传完别乱点。
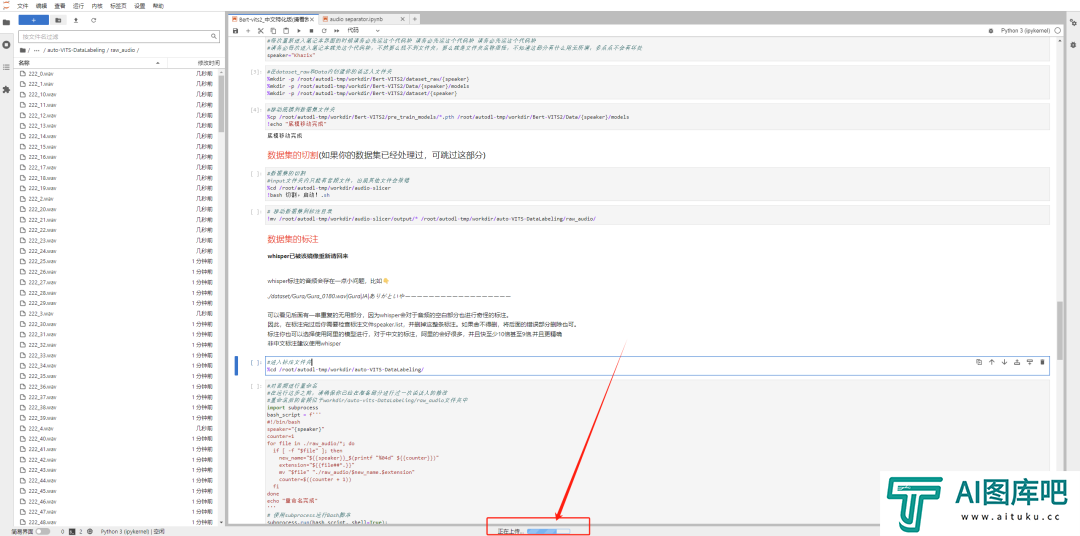
传完以后,我们就要进行数据集的标注了。这两个代码块,连这运行就行。
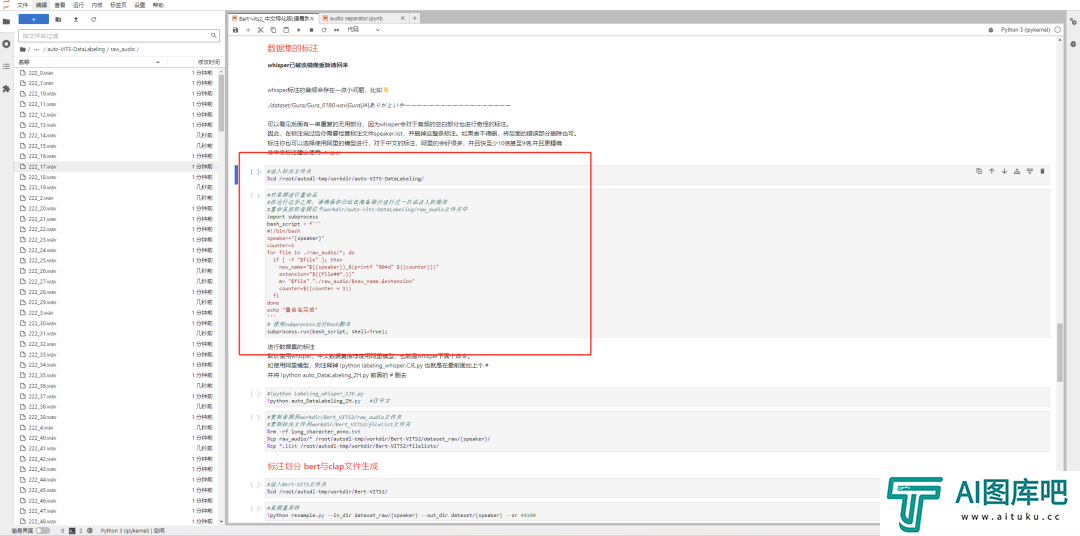
然后我们开始正儿八经的标注,继续运行代码块就行。数据集嘛,标注一下效果才好,你懂的。
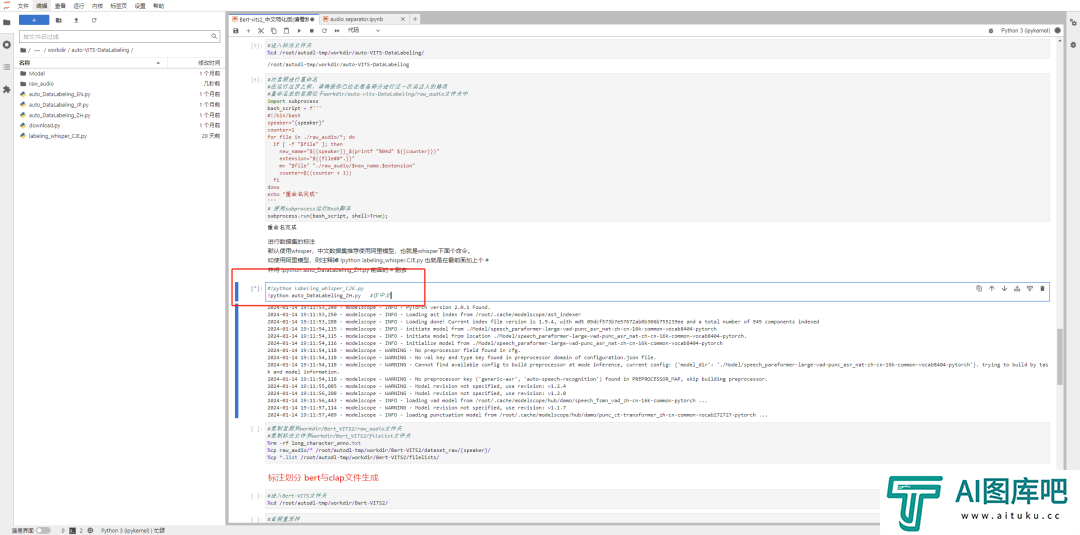
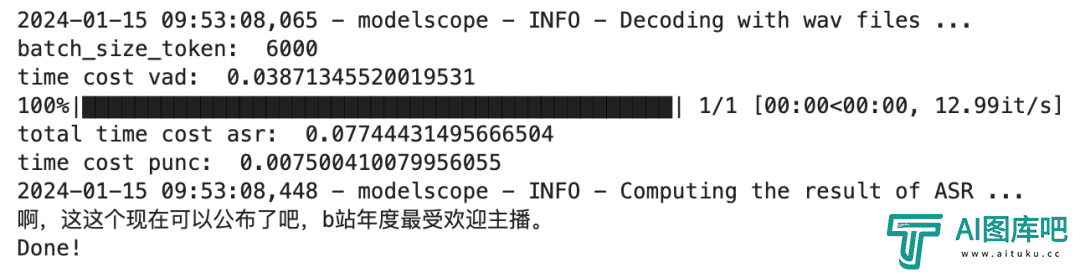
这一步会有一点点久,毕竟得一条条语音识别出来。我1093条音频,大概花了9分钟,你们可以自己类推一下下~
直到看到Done的提示,说明标注就完成啦。
然后就是后面的5步,生成出各种东西,这5个代码块你也不需要改任何东西,看着右上角圆圈状态,无脑点击运行就行。
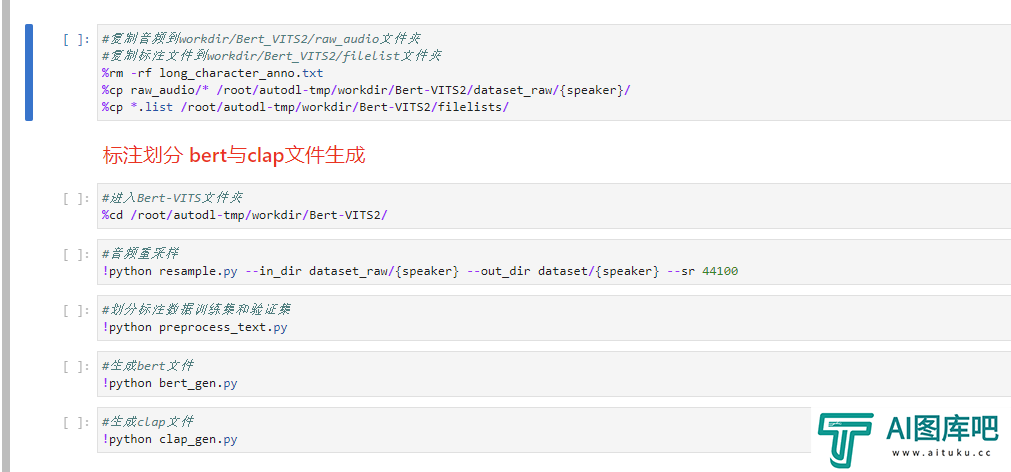
每一步都运行完的提示大概长这样,你们可以对着验证一下:
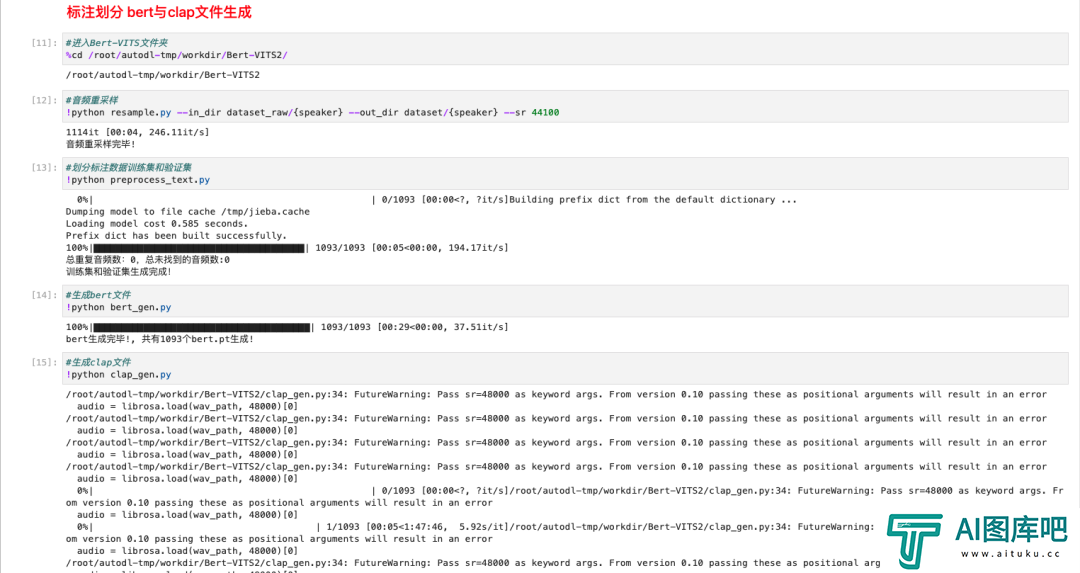
最后,我们就要开始最后的一步!训练了!!!
训练一共是3步,前两步还是跟之前一样,无脑点击就行。
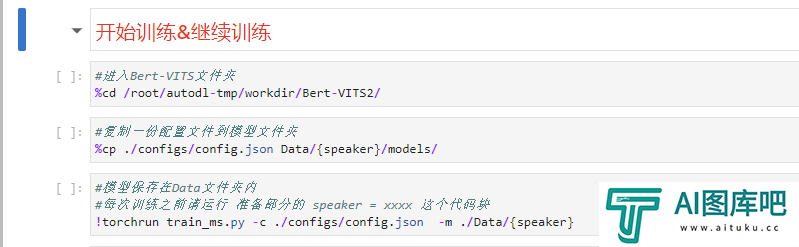
前两部运行完之后,等一等,停手!先别点第3步那个开始训练的代码块,而是返回顶部,找到我们最开始的speaker="Khazix"那个代码块,运行一下后,再回来开始训练!!!就是这个:
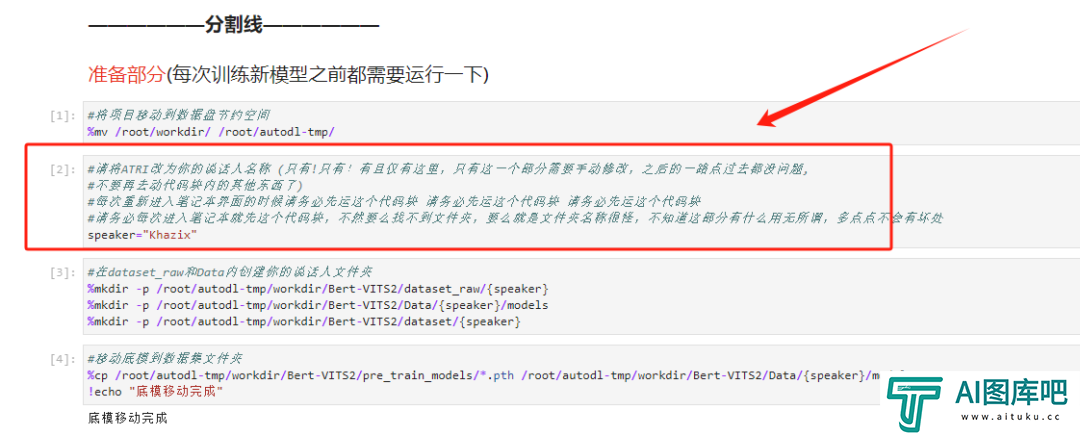
一定要,运行完以后,再回来开始训练!!要不然到时候报错了别来问我= =
OK,一切完毕,直接点击训练的那个代码块。如果你一切按我的来,从选机器开始,到最后的运行,基本是不会有BUG或者报错的,都能跑起来。你就能看到开始蠕动的进度条了。
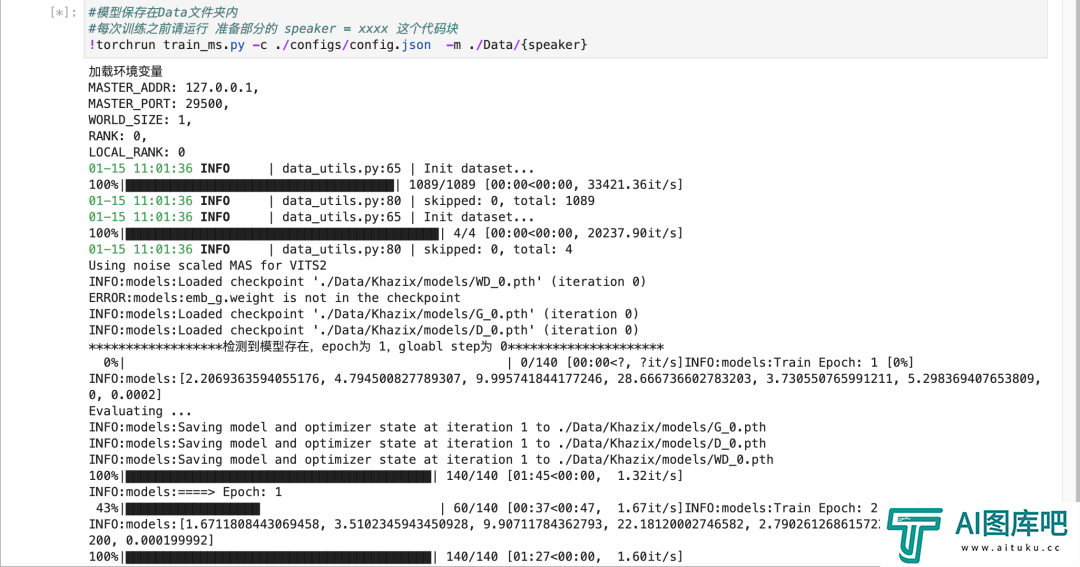
等着就行,跟SVC类似,每1000步会在autodl-tmp/workdir/Bert-VITS2/Data这个文件夹里保存一个模型,我一般推荐4000步、5000步的模型可以听听效果了,没有大问题的话,就可以继续往后炼,10000步的模型差不多就可以用了,但是我还是推荐你10000步以后的每个保存下来的模型,都听一下,挑个最好的。
最后,模型差不多了,我们就要开始推理了~也就是真正的把文字转成语音了~推理我建议还是上云推理,本地推理要求最低也是8G显存,挺高的。。。像我这种*3060想都不敢想。
推理第一步,先去改一下配置文件,因为这个项目比较新,所以用户体验不是特别好,大家忍耐一下,马上就完事了~
我们在autodl-tmp/workdir/Bert-VITS2这个路径下,找到一个叫config.yml的文件。双击点开它。
找到105行。
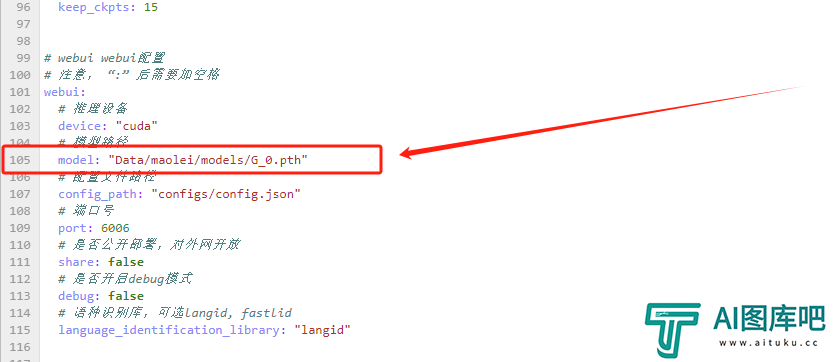
把这行的路径model: "Data/maolei/models/G_0.pth",换成你自己的。
比如我的说话人最开始设的叫Khazix,现在我想用5000步的模型去做推理,那我就把这行改成:
model: "Data/Khazix/models/G_5000.pth"
标红的这块就是需要你去修改的。改完以后,记得多按几下Ctrl+S保存。
然后,保持在autodl-tmp/workdir/Bert-VITS2目录下,再点击右上角的+号,再点终端,进入命令行页面。
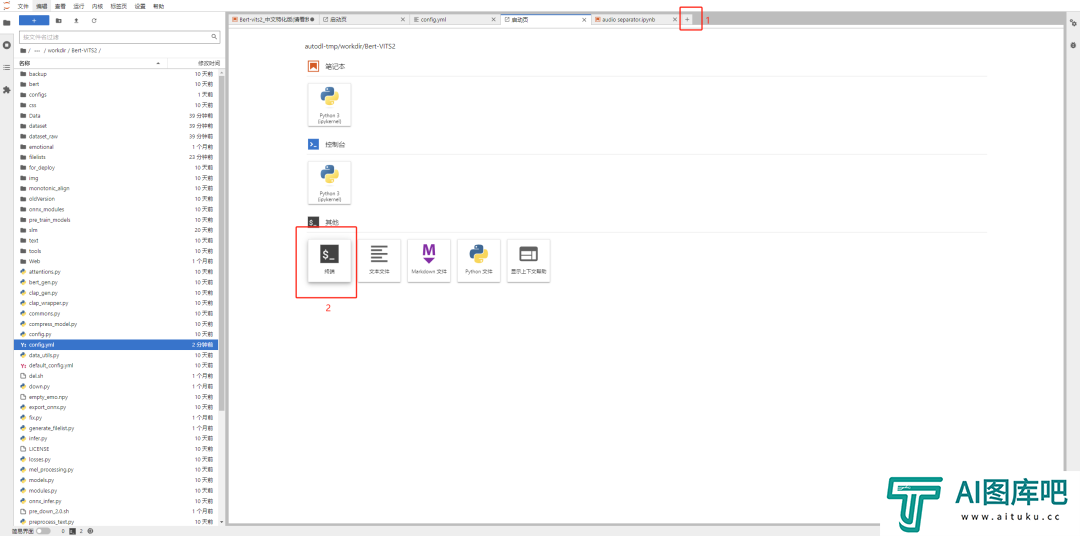
输入代码:
python webui.py
就会出来一串推理地址:

如果遇到报错,可以先把那边训练给停了,按顶上的方块停止按钮就行,下次再开是接着训练的,不影响。
看到这个地址后,别直接点进去,会啥也看不到的,因为这是云机器的本地连接,所以我们要通过一些额外手段接进去。
回到AutoDL的控制台首页,点击这个自定义服务,就可以进去了。
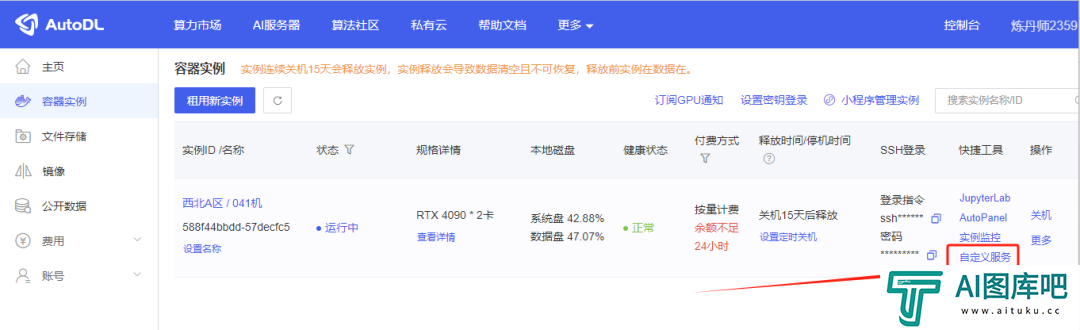
然后,你就可以看到推理的WebUI了。

在左上角正常输入你的文字内容就行。
有个有趣的东西是音频Prompt,你可以再传一段音频上去,把这段音频的风格作为Prompt,他就可以生成差不多效果的音频。
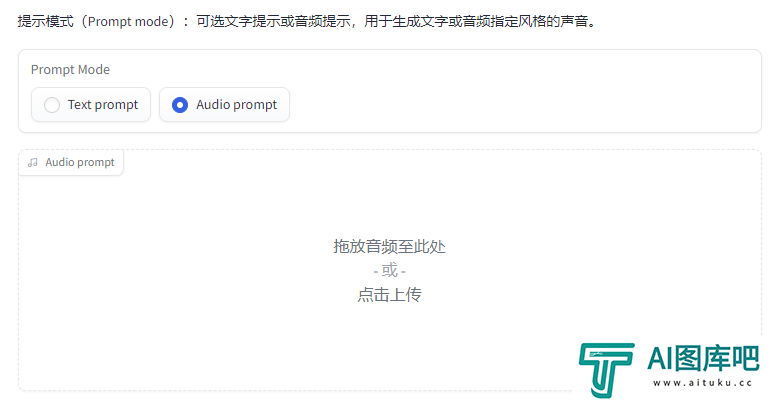
比如我传了一段峰哥8秒的说话切片作为参考,然后所有参数都不变,就生成了这么一段话。
实在是太还原了,除了气口这个老大难问题,其他的都几乎一样,连峰哥语气词都还原出来了。
下面的这些参数,其实只用看最后一个Length那个就行,那个是语速,有时候AI会贼快,所以可以适当的加大参数,参数越大越慢,另外三个最好别动,默认就行。
最后,你训练的模型如果要保存下来,记得去autodl-tmp/workdir/Bert-VITS2/Data/你的文件夹名字/models里,把三个模型下载下来,一定要保证后缀是一样的,下次直接传到同一个文件夹里,就可以继续推理了。
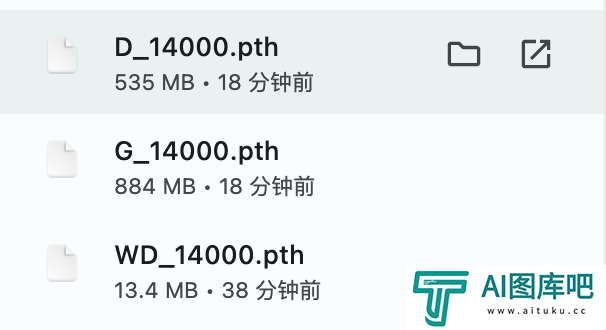
以上,就是这一版Bert-Vits2中文特化版的全部用法。
说实话,蹚坑挺累的,作为一个不懂技术的,我蹚坑真的蹚了好几个晚上,没有前路,只能自己把各种报错原因拿去跟GPT对话,然后研究怎么整。。。
但是好在,最后还是OK了。
希望,大家都能发挥出它的强大,用AI,真的去做一些有趣的事。
-
![小度全新AI硬件将于百度世界大会发布丨智谱AI、即梦AI上线新一代视频生成模型丨OpenAI安全系统团队负责人离职]() 小度全新AI硬件将于百度世界大会发布丨智谱AI、即梦AI上线新一代视频生成模型丨OpenAI安全系统团队负责人离职
小度全新AI硬件将于百度世界大会发布丨智谱AI、即梦AI上线新一代视频生成模型丨OpenAI安全系统团队负责人离职【AI奇点网2024年11月11日早报】本站每日播报AI业界最新资讯,触摸时代脉搏,掌握未来科技动向。事不宜迟,点击查看今日AI资讯早餐。
2025-01-08 11:46:33 -
![字节跳动内测豆包通用图像编辑模型SeedEdit丨Grok聊天机器人免费版内测丨月之暗面Kimi创始人被提起仲裁]() 字节跳动内测豆包通用图像编辑模型SeedEdit丨Grok聊天机器人免费版内测丨月之暗面Kimi创始人被提起仲裁
字节跳动内测豆包通用图像编辑模型SeedEdit丨Grok聊天机器人免费版内测丨月之暗面Kimi创始人被提起仲裁【AI奇点网2024年11月12日早报】本站每日播报AI业界最新资讯,触摸时代脉搏,掌握未来科技动向。事不宜迟,点击查看今日AI资讯早餐。
2025-01-08 11:25:01 -
![李彦宏:文心大模型日调用量超15亿丨百度发布文心「iRAG」文生图技术丨小度AI智能眼镜发布,搭载大模型边走边问]() 李彦宏:文心大模型日调用量超15亿丨百度发布文心「iRAG」文生图技术丨小度AI智能眼镜发布,搭载大模型边走边问
李彦宏:文心大模型日调用量超15亿丨百度发布文心「iRAG」文生图技术丨小度AI智能眼镜发布,搭载大模型边走边问【AI奇点网2024年11月13日早报】本站每日播报AI业界最新资讯,触摸时代脉搏,掌握未来科技动向。事不宜迟,点击查看今日AI资讯早餐。
2025-01-08 10:58:46 -
![巧妙利用这两个AI产品,让你的国庆出行没有废片]() 巧妙利用这两个AI产品,让你的国庆出行没有废片
巧妙利用这两个AI产品,让你的国庆出行没有废片这两天就有朋友来问我,有没有那种能修图的AI,就是扩图+消除啥的傻瓜好用的。大家大概的需求总结一下其实就两,AI消除+AI扩图。
2025-01-08 10:34:49 -
![OpenAI初步谈妥融资70亿美元:最大金主微软追加投资10亿,苹果退出]() OpenAI初步谈妥融资70亿美元:最大金主微软追加投资10亿,苹果退出
OpenAI初步谈妥融资70亿美元:最大金主微软追加投资10亿,苹果退出据华尔街日报报道,苹果公司退出了对 OpenAI 的新一轮融资谈判,而微软则计划向 OpenAI 追加约 10 亿美元的投资。
2025-01-08 10:14:21 -
![详解Meta全新大模型Llama 3.2系列:多模态视觉识别能力媲美OpenAI GPT-4o]() 详解Meta全新大模型Llama 3.2系列:多模态视觉识别能力媲美OpenAI GPT-4o
详解Meta全新大模型Llama 3.2系列:多模态视觉识别能力媲美OpenAI GPT-4oMeta公司推出了Llama 3 2,也是它首款能够理解图像和文本的旗舰视觉模型。包含中型和小型两个版本,以及更轻量化可用于手机端侧的纯文本模型。
2025-01-08 09:46:43













-
![怎么快速给模特换装_怎么用stable diffusion给模特换装]() 怎么快速给模特换装_怎么用stable diffusion给模特换装
怎么快速给模特换装_怎么用stable diffusion给模特换装本篇教程主要运用StableDiffusion这个工具来进行操作,下面会通过几个小案例,给大家展示不同需求下,我们该如何使用StableDiffusion来辅助我们完成服装效果展示。本教程适用于电商设计场景、摄影场景等多个运用人物设计的实战中
2024-12-23 13:57:15 -
![万万没想到,兵马俑都开始跳「科目三」:阿里云通义千问APP打造“全民舞王”视频创作工具,实测效果大赞]() 万万没想到,兵马俑都开始跳「科目三」:阿里云通义千问APP打造“全民舞王”视频创作工具,实测效果大赞
万万没想到,兵马俑都开始跳「科目三」:阿里云通义千问APP打造“全民舞王”视频创作工具,实测效果大赞兵马俑跳《科目三》,是我万万没想到的。有人借助了阿里云之前走红的AI视频生成技术——「Animate Anyone」,生成出来了这个舞蹈片段。
2024-12-13 16:46:26 -
![AIGC落地实践!四招帮你快速搞定运营设计]() AIGC落地实践!四招帮你快速搞定运营设计
AIGC落地实践!四招帮你快速搞定运营设计回顾这一年,随着 AIGC 浪潮的爆发,在掌握AI工具已经成为设计师必备技能。今天这篇文章,通过三个案例流程拆解带大家从新时代设计工作流,到必备「四大招式」,到图标设计六大方向,到训练专属模型,再到全流程手把手拆解设计项目,绝对干货满满
2024-12-18 16:57:17 -
ChatGPT怎么本地登录_GPT怎么使用_GPT本地项目
本期就ChatGPT的这次更新再次将完全新人使用指南提上日程,并对此次更新做些设想和想象。希望大家喜欢!
2024-12-19 07:41:20 -
![stable diffusion初识_stable diffusion跟其他工具有什么区别]]() stable diffusion初识_stable diffusion跟其他工具有什么区别]
stable diffusion初识_stable diffusion跟其他工具有什么区别]关于Stable Diffusion的内容很多,在本篇教程里,我会先为你介绍Stable Diffusion模型的运行原理、发展历程和相较于其他AI绘图应用的区别。
2024-12-24 13:45:31 -
![PikaAI怎么用_PIkaAI怎样生成视频_AI视频生成器Pika怎么用_AI视频生成工具Pika教程]() PikaAI怎么用_PIkaAI怎样生成视频_AI视频生成器Pika怎么用_AI视频生成工具Pika教程
PikaAI怎么用_PIkaAI怎样生成视频_AI视频生成器Pika怎么用_AI视频生成工具Pika教程Pika这款工具7月份在AIGC界横空出世,被圈内誉为目前“全球最好的文本生成视频AI工具”之一,也被认为是另外一款知名AI视频生成工具Runway的强有力挑战者。
2024-12-25 13:35:53 -
![如何使用 ChatGPT 调试代码]() 如何使用 ChatGPT 调试代码
如何使用 ChatGPT 调试代码当您的代码出现问题时,您可以向 ChatGPT 提供故障代码和问题描述。AI 工具将尝试识别并纠正问题。
2024-12-31 12:01:41 -
![stable SR脚本安装_stable diffusion脚本网站]() stable SR脚本安装_stable diffusion脚本网站
stable SR脚本安装_stable diffusion脚本网站上节课我们讲的4xUltraSharp是不是觉得已经很强了! 那么如果我拿出Stable SR脚本你应该如何应对呢?
2024-12-31 13:49:18 -
![零基础2天速成!白嫖「秋叶」官方AI绘画课程,卷死同事]() 零基础2天速成!白嫖「秋叶」官方AI绘画课程,卷死同事
零基础2天速成!白嫖「秋叶」官方AI绘画课程,卷死同事和「秋叶」一起学AI绘画,掌握Stable Diffusion、Midjourney的使用方法,开展AI绘画副业,搞钱!?
2024-12-17 12:53:01 -
openpose如何自定义角色_个性化角色姿势怎么定制_Controlnet深度解析
在设计角色姿势时,如何使用openpose进行姿势自定义,以及如何通过拍摄照片或使用第三方后期软件?同时,虚幻引擎对于角色姿势的编辑也很重要,本视频就并展示了如何使用优异商城中的免费资源来创建人物角色。
2024-12-19 11:43:51


![stable diffusion初识_stable diffusion跟其他工具有什么区别]](http://www.aituku.cc/uploadfile/2024/1224/d3a1bbf8bad6e281f82a2168727dfba1.png)



